Googleにインデックスされない原因と対処法12選

新しくサイトやページを作っても、Googleにインデックスされずに困ったことは無いでしょうか?インデックスされない原因の多くは、URLを発見されていないケースが多いですが、それ以外にも設定ミスなどでインデックスされないケースもあります。本記事ではインデックスされない原因と改善案を12個のケースごとに詳しく解説しています。
インデックスされるための前提条件
インデックスされない原因について解説する前に、Googleにインデックスされるための前提条件を解説します。
インデックスされるための前提条件は以下の2点です。
- ページをクロールしてもらう必要がある
- インデックスには条件がある
ページをクロールしてもらう必要がある
Googleにインデックスされるには、大前提としてGoogleのクローラーにページを発見してもらいクロールしてもらう必要があります。
Googleはロボット型の検索エンジンのため、スパイダーと呼ばれるクローラーがWEBサイトのURLを辿ることで自動的にインターネット上にある世界中のWEBサイトを巡回し、ページ内のテキストや画像・動画などの情報を収集します。これをクロールと言います。
なんらかの理由でクローラーがURLを発見出来ない場合や、ページをクロール出来ない場合はクローラーがページ内の情報を収集することが出来ないため、Googleはインデックスすることができません。
インデックスには条件がある
Googleはクロールしたページを全てインデックスさせるわけではありません。
ページをクロールした後にGoogleは収集した情報がデータベース内にある情報と重複していないかどうか、正規ページであるかどうかを確認します。また、その際にページのコンテンツ品質やメタデータの内容、ページのデザインなども考慮し、最終的にインデックス登録をするかどうかを決定します。
つまり、既にインターネット上に似たようなコンテンツがある場合や、検索結果に表示する価値のないページの場合はインデックスされる条件から外れます。これらを踏まえた上で、インデックスされているかどうかを正確に確認する方法を次の項目で解説します。
インデックスされているか確認する方法
まずは、検索結果にページが表示されない場合、インデックスされていない事が原因なのかを確認します。Googleにインデックスされているか確認するには、Google Search Consoleを使って確認する方法と「site:」を使って検索結果から確認する方法の2パターンあります。
それぞれの違いは下記になります。
- 「site:」:インデックスされているかどうか分かる
- 「Google Search Console」:インデックスされていない原因も分かる
それぞれ詳しく解説します。
「site:URL」で検索して確認
site:(検索演算子)を使ってGoogle検索をおこなうと、インデックスされているかどうか確認することが出来ます。
やり方は簡単です。
- Googleの検索窓に、site:を入力します。
- site:の後ろにインデックスされているか確認したいURLを入力します。
インデックスされている場合は、検索結果にファビコン・URL・ページタイトル・ページの説明文・リッチリザルトが表示されます。
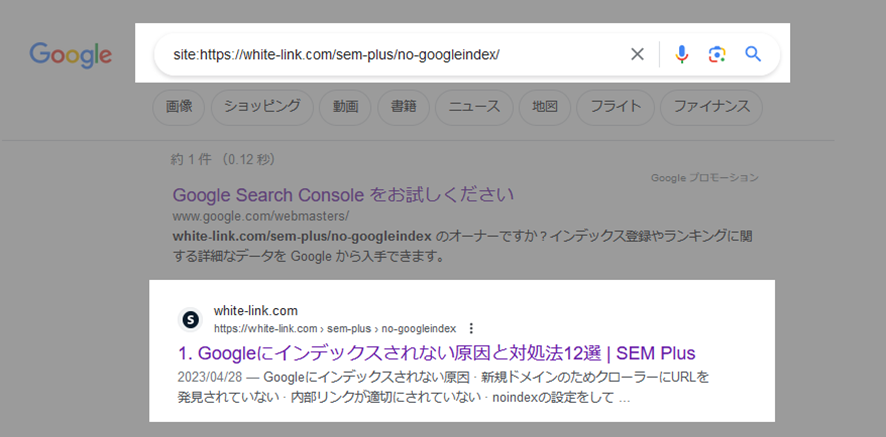
インデックスされていない場合は、「site:入力したURLに一致する情報は見つかりませんでした。」と検索ヒントが検索結果に表示されます。
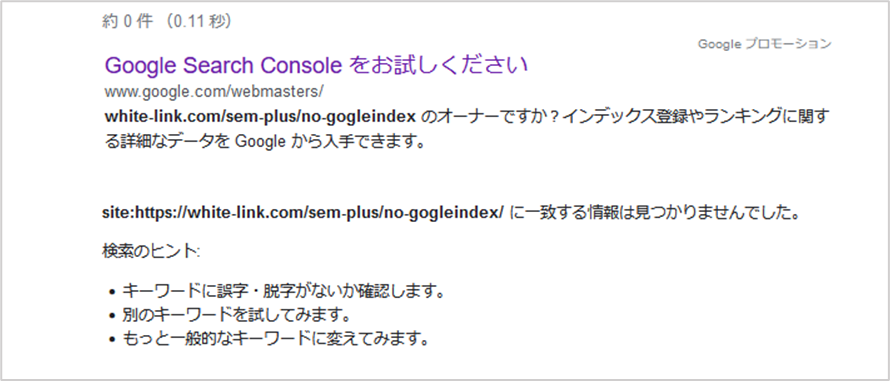
尚、実際にはインデックスされている場合でも「site:URL」の検索結果に表示されない場合があります。より正確な結果を知りたい場合は、次に紹介するGoogle Search Consoleを使ってインデックスを確認しましょう。
「Google Search Console」で確認する
Google Search Consoleを使うと、より正確にインデックスされているどうかを確認することが出来ます。
確認する手順は以下になります。
- Google Search Consoleにログインする
- メニューから「URL検査」をクリック
- 検索窓に確認したいページのURLを入力する
インデックスされている場合は、「URLはGoogleに登録されています」と表示されます。
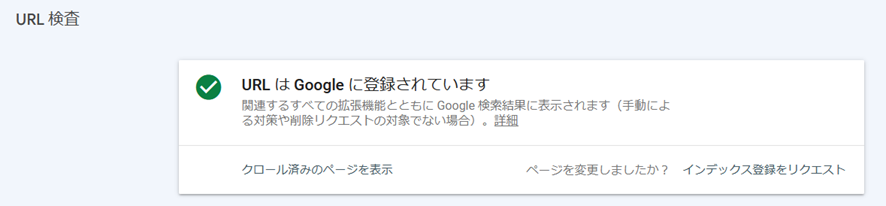
インデックスされていない場合は、「URLがGoogleに登録されていません」と表示されます。
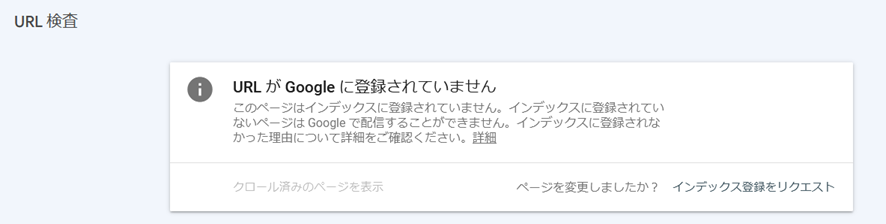
このように、URL検査を使う事でより正確なインデックス状況を把握することが出来ますが、URL検査ツールには1日の利用上限(10回程度)があります。
インデックスされない原因を分けると大きく2つある
インデックスされていない原因を大きく分けると、「技術的な問題」と「品質の問題」の2つに分けられます。どちらの問題なのかによって、改善の打ち手が異なるためそれぞれ覚えておきましょう。
技術的な問題でインデックスされていない
インデックスされない原因の多くは技術的な問題が原因です。
技術的な問題とは、サイト管理者の設定やサイトの仕様によってクローラーがページを読み込めなかったり、インデックスが許可されていない状態を指します。
WEBサイトを長く運用していると、ページの統合や削除、ドメイン変更などをおこなうことが多くありますが、その際に間違った設定をしてしまうと技術的な問題が発生しインデックスされなくなります。
技術的な問題は、Google Search ConsoleのURL検査ツールを使うことで特定することができます。

URL検索をおこなうと、上記画像のように「Googleのクローラーがどのような経由でページを「検出」したのか?」「クロールされた日時や拒否されていないか」、「インデックス登録が拒否されていないか」などを確認することが出来ます。
品質の問題でインデックスされていない
サイトやページの品質に関する問題がある場合も、インデックスされない原因となります。品質の問題とは、Googleがユーザーにとって価値の低いページと判断した事でインデックスされなかったケースを指します。
こちらは技術的な問題とは異なり、サイト管理者がページの品質を1つ1つ改善していく必要があります。
例えば、他サイトのページを少し変えただけのページ、広告だらけのページ、事実に反する内容や差別的な内容が記載されているぺージなどは品質の低いコンテンツと見なされるため改善しましょう。
Googleにインデックスされない原因12選
WEBサイトが、Googleにインデックスされない原因は以下になります。
- 新規ドメインのため、クローラーにURLを発見されていない
- noindexの設定をしている
- 別のページにリダイレクトしている
- canonicalタグで別のページを正規ページとして指定している
- サーバー側でGoogleのクローラーを拒否している
- robots.txtでクロールを拒否している
- ネットワークの問題で500エラーが発生しサイトを閲覧できない
- Googleからペナルティを受けている
- コンテンツの品質が低い
- 重複コンテンツがある
- ログインが必要な有料コンテンツや会員専用コンテンツ
- サイト構造が複雑
新規ドメインのため、クローラーにURLを発見されていない
新規ドメインがインデックスされない原因の殆どは、クローラーにURLを発見されていないためです。検索エンジンのクローラーは、インターネット上に存在するページに貼られたリンクを辿って、サイトやページのURLを検出しています。
新規ドメインのサイトは、外部サイトとリンクで繋がっていないケースが多く、クローラーから発見されにくいため、インデックスされるまでに時間がかかる場合があります。
noindexの設定をしている
ページにnoindexタグの設定をしている場合も、インデックスされません。
noindexタグとは、「クローラーにインデックスさせないでほしい」と指令を送る役割があるため、管理画面のURLや低品質なページなど、検索結果に表示させたくない場合に使用します。
稀に「ページアップ前のテストページにnoindexタグを設定していたが、公開後にnoindexタグを削除し忘れ公開していた」というケースがあるため、サイト公開後にインデックスされない場合は一度確認してみましょう。
尚、noindexが原因でインデックスされていない場合、Googleサーチコンソールのインデックス登録レポート上で「URLにnoindexが指定されています」と表示されます。
ページのhtml内からnoindexタグを削除した上で、Google Search ConsoleのURL検査から「インデックス登録リクエスト」をおこなえばインデックスされ検索結果に表示されます。
noindexタグについては、下記のページで解説しています。
【関連記事】:noindexタグとは?設定方法(書き方)と確認方法・SEO効果について
別のページにリダイレクトしている
301リダイレクトを使って別のページにリダイレクトしている場合、リダイレクト元のページはインデックスされません。301リダイレクトはぺージの恒久的な移動を意味するため、検索エンジンはリダイレクト先のページをインデックスします。
尚、リダイレクトが原因でインデックスされていない場合、Googleサーチコンソールのインデックス登録レポート上で「ページにリダイレクトがあります」と表示されます。
誤ってリダイレクトの設定をしてしまい、インデックスさせたいページがインデックスから削除された場合は、リダイレクトの設定を解除した上で、サーチコンソールのURL検査からインデックスリクエストをおこなうことで再度インデックスされるようになります。
canonicalタグで別のページを正規ページとして指定している
canonicalタグで、別のページを正規ページとして指定している場合、指定元のぺージはインデックスされません。canonicalタグとはURLを正規化する場合に使うタグで、ページの内容が重複している場合や、1つのページで複数のURLがある場合に評価を1つのページに集めるために使用します。
canonicalタグで別のURLを正規指定した場合、検索エンジンは正規指定されたページをインデックスさせ、canonicalタグを設定した元のページはインデックスしません。
尚、URL検索の結果画面の「ユーザーが指定した正規URL」にインデックスさせたいページとは別のURLが表示されている場合は別のURLをcanonicalで正規指定しているため、設定を変更しましょう。
canonicalタグについては、下記のページで解説しています。
【関連記事】:canonicalタグとは?書き方とURL正規化が必要なケースを解説 | SEM Plus
サーバー側でGoogleのクローラーを拒否している
サーバー側の設定でクローラーを拒否している場合も、インデックスされない原因となります。よくあるケースとしては、サーバー側で海外のIPアドレスを拒否しているケースです。
Googlebotは、アメリカのIPアドレスからサイトにアクセスしているため、サーバー側で海外のIPアドレスからのアクセスを拒否した場合、Googlebotがサイトにアクセスできずページを読み込めないためインデックスすることができません。
サーバー会社によっては初期設定で海外IPを遮断してる場合があるため、サイト公開後インデックスされない場合はサーバー側の設定を確認してみましょう。
また、任意で海外からのアクセスを拒否したい場合は、Googlebotからのアクセスは許可するように設定しましょう。
robots.txtでクロールを拒否している
robots.txtとは検索エンジンのクロールを管理するファイルです。robots.txtファイル内に「Disallow」でURLを指定した場合、指定されたURLもしくはディレクトに属するページのクロールを拒否していることになります。
この場合、Googleはクロールが出来ないため当然インデックスはされません。
robots.txtでクロールを拒否している場合は、Googleサーチコンソールのページインデックスレポートに、「URLがrobots.txtによってブロックされています。」と表示されます。「robots.txt 」の記述内容を修正して再度アップロードすれば自動的にクローラーが巡回してインデックスされます。
尚、robots.txtでクローラーを拒否していても、外部のサイトからリンクがある場合などはページがインデックスされる場合があります。この場合は、Googleサーチコンソールのレポートに「robots.txt によりブロックされましたが、インデックスに登録しました」と表示されます。
robots.txtについては、下記のページで詳しく解説していますのでご覧ください。
【関連記事】:robots.txtとは?書き方のルール・設定方法を解説
ネットワークの問題で500エラーが発生しサイトを閲覧できない
サーバーの過負荷や、インターネット接続の問題、DNSの設定ミスなどによって500エラーが発生すると、クローラーがページにアクセスできなくなるためインデックスされません。
一時的な500エラーであれば問題ありませんが、頻繁に発生すると検索エンジンはそのサイトやページが信頼性が低いと判断し、クローリングやインデックス作成を避ける可能性があります。
500エラーを発生させないためには、サーバーの監視を強化し、エラーログを定期的にチェックして問題の早期発見と修正に努めることが重要です。また、サーバーのリソースを適切に管理し、WEBサイトのトラフィックが予想を超えないようにしましょう。
500エラーについては、下記のページで解説しています。
【関連記事】:500エラー(Internal Server Error)とは?原因と解決方法を解説
Googleからペナルティを受けている
Googleからペナルティを受けているWEBサイトは、インデックスが削除される可能性があります。GoogleはGoogleウェブ検索のスパムに関するポリシーで、リンクスパムやクローキング、コンテンツの自動生成など検索結果を意図的に操作する行為を禁止しています。
Googleからペナルティを受けているかどうかはGoogle Search Consoleの「セキュリティと手動による対策」から確認できます。
通常は「問題は検出されませんでした」と表示されますが、ペナルティを受けた場合はメッセージが届くため、原因を修正した上でGoogle Search Consoleから「再審査リクエスト」をおこない、ペナルティを解除します。尚、リクエスト後、約2〜4週間程度でインデックスされます。
Googleのペナルティについては、下記のページで解説しています。
【関連記事】:Googleペナルティとは?解除方法と期間・確認(診断)方法を解説
コンテンツの品質が低い
低品質なコンテンツは、インデックスされづらい傾向があります。なぜなら、内容が薄かったりユーザーにとって役に立たないコンテンツを検索結果に表示してもGoogleの信頼を低下させることに繋がるためです。
低品質なコンテンツの代表的な例を記載するので、インデックスされない場合は該当する項目が無いか確認してください。
- ツールなどで自動的に生成されたコンテンツ
- アフィリエイトリンクをクリックさせることだけを目的としたページ
- サイトの運営者の許可を得ずにコピーしたテキストを掲載したコンテンツ
- 外部ページへ誘導することだけを目的に作成されたページ
上記以外にも、他サイトの語尾を変更しただけのコンテンツや、内容が薄いコンテンツなどは低品質なコンテンツに該当します。
重複コンテンツがある
WEBサイト内に内容が重複しているページが複数ある場合、どちらか片方のページしかインデックスされません。
例えば、Titleと見出しを変えただけのぺージをエリアごとに作成している場合や、コラム内でテーマが類似している記事がある場合は、重複コンテンツになるため、ページごとに個別のテーマを設定し独自のコンテンツを作成する必要があります。
また、オンラインショップの商品で、同一商品でカラー別にそれぞれURLがある場合も同様に、Googleはどれか1つのURLだけをインデックスさせ検索結果に表示させます。
Googleの検索セントラルにも以下のように記載されています。
Googleは、固有の情報を持つページをインデックスに登録して表示するよう努めています。たとえば、記事ごとに「通常」バージョンのサイトと「印刷」バージョンのサイトがあり、どちらもnoindexメタタグでブロックされていない場合、Googleはどちらか一方を選択して登録します。
重複コンテンツの作成を避ける Google検索セントラル
このケースの場合、全てのページをインデックスさせるのは難しいため、類似するページの中で一番検索結果に表示させたいページをcanonicalタグで正規指定するのがSEOでのベストプラクティスです。
重複コンテンツについては、下記のページで解説しています。
【関連記事】:重複コンテンツとは│基準と調べ方・SEO対策の影響を解説
ログインが必要な有料コンテンツや会員専用コンテンツ
有料ページや、ニュースページなどの閲覧にパスワードが必要なペイウィールコンテンツの場合、クローラーがページにアクセスできないため通常インデックスされません。
このような認証が必要なページをGoogleに読み込ませてインデックスさせようとすると、ユーザーと検索エンジンで見れるコンテンツが異なるためクローキングに該当しペナルティを受ける可能性があります。
そこで、ログインが必要な有料コンテンツや会員専用コンテンツをインデックスさせたい場合は、フレキシブルサンプリングを実装します。構造化データでフレキシブルサンプリングを実装すればクローキングに該当することなく、インデックスさせることが出来ます。
サイト構造が複雑
WEBサイトの構造が複雑、または階層が深すぎると、検索エンジンのクローラーが全てのページを効率的に発見し、クロールすることが難しくなるため、インデックスされない原因になります。
クローラーは基本的にリンクを辿ってWEBサイト内を移動しますが、構造が複雑だと、重要なページが深い階層に埋もれてしまい、クローラーが見落とす可能性が高まります。
サイトの構造をシンプルにする、階層を浅くする事で、クローラーがサイト内の全てのコンテンツに簡単にアクセスできるようにします。
SEOに効果的なサイト構造については、下記のページで解説しています。
【関連記事】:サイト構造がSEOで重要な理由と設計方法を紹介
インデックスされない場合の対策方法
ページがインデックスされない場合におこなう、効果的な対策方法は以下の5つになります。
- XMLサイトマップを送信する
- インデックス登録リクエストを送信する
- 被リンクを増やす
- 内部リンクを適切に設置する
- コンテンツの品質を改善する
それぞれ詳しく解説します。
XMLサイトマップを送信する
新規に公開したサイトを早くインデックスさせたい場合は、サーチコンソールから「xmlサイトマップ」を送信しましょう。XMLサイトマップとはサイトの構造やサイト内にあるURLをまとめたファイルのことで、検索エンジンにサイトの構造を伝えるために使用します。
XMLサイトマップを作成しGoogle サーチコンソールから送信すると、クローラーはリンクを辿るだけでは発見できなかったURLを認識することができるため、XMLサイトマップ内に記述されたURLをクロールしインデックスすることができます。
XMLサイトマップの作成方法と送信方法については、下記のページで解説しています。
【関連記事】:XMLサイトマップとは?必要性と作り方・設定方法を解説
インデックス登録リクエストを送信する
Google Search ConsoleにあるURL検索ツールからインデックス登録リクエストを送信することで、検索エンジンに直接URLの存在を伝えることが出来ます。
新しくページを作成した場合や、リライトをおこなった際に、インデックス登録リクエストをすればすぐにページをクロールしてくれるため、インデックスの促進だけではなく、検索結果に表示される速度も早まります。
インデックス登録リクエストはURLを個別に送信することしか出来ないため、リニューアル後にサイト内に新規URLが大量に増えた場合はXMLサイトマップを活用しましょう。
インデックス登録リクエストのやり方については、下記のページで解説しています。
【関連記事】:URL検査ツールとは?使い方とできることを解説【サーチコンソール】
被リンクを増やす
SEO外部対策をおこない被リンクを増やすことで、クローラーは外部サイトに貼られたリンクを辿ってURLを発見できるようになるためインデックスされやすくなります。
Googleは、被リンクを「第三者からの推薦」として捉え、質の高い被リンクを多く獲得しているサイトは人気があり、価値のあるコンテンツを提供しているサイトとみなしドメインの評価を高めます。
ドメインの評価が高まると、クローラーがそのサイトをより頻繁に訪問するようになり、新規ページや更新されたコンテンツがインデックスされるまでの時間が短縮されます。
被リンクの獲得方法ついては、下記のページで解説しています。
【関連記事】:被リンクとは|SEO効果・増やすポイントを分かりやすく解説
内部リンクを適切に設置する
WEBサイトが検索エンジンにインデックスされない問題に対処する上で内部リンクの設置も重要です。クローラーは内部リンクを辿ってサイト内のページを発見しクロールするため、全てのページを内部リンクで繋げてクローラーがサイト内を巡回しやすいようにする必要があります。
例えば、グローバルナビゲーション・パンくずリストの設置やフッターエリアに主要ページへのリンクを設置することで、クローラーはサイト内の主要なページへアクセスしやすくなります。
さらに、新規ページを作成した際は、関連するページからの内部リンクや、トップページなど主要なページから内部リンクを設置することでURLが発見されインデックスされやすくなります。
コンテンツの品質を改善する
ページがクロールされ技術的な問題が発生していないにも関わらず、インデックスされない場合は、コンテンツの品質に原因があります。
検索エンジンから評価されるには、その分野の専門家がページのテーマに対して検索ユーザーが求めているコンテンツを作成している事と、ページのテーマを分かりやすく表したキーワードを含めたTitleタグやhタグが設定されている必要があります。
また、ヘルプフルコンテンツアップデート以降、低品質なコンテンツがある場合はサイト全体の評価が下げられるようになっています。そのため、既にコンテンツを作成している場合は低品質なコンテンツを削除するか、リライトをおこないサイト全体の品質を改善する必要があります。
まとめ
Googleにインデックスされない原因を紹介してきましたが、インデックスされない殆どのケースがサイト側の問題です。小規模なサイトであれば、本記事を読みそれぞれの原因について深く理解することで、すぐに原因を解明することができ対策できるようになります。
ただし、データベースを扱う大規模サイトの場合は、テクニカルな施策をおこなわないと多くのぺージがインデックス未登録になる可能性があるため、専門家が必要になるケースも多くあります。
本記事でインデックスされない原因を解決できない場合は、一度弊社までご相談くださいませ。

この記事を書いたライター

SEMを軸にSEOの施策を行うオルグロー内の一部署。 サイト構築段階からのSEO要件のチェックやコンテンツ作成やサイト設計までを一貫して行う。社内でもひときわ豊富な知見を有する。またSEO歴15年超のノウハウをSEOサービスに反映し、3,000社を超える個人事業主から中堅企業までの幅広い顧客層に向けてビジネス規模にあった施策を提供し続けている。
ぜひ、読んで欲しい記事
-
 SEO対策Googleクローラーとは?仕組みと申請方法・巡回頻度を高めるやり方2026/01/16
SEO対策Googleクローラーとは?仕組みと申請方法・巡回頻度を高めるやり方2026/01/162026/01/16
-
 SEO対策h1タグとは?初心者向けにSEO効果と正しい使い方を徹底解説2026/01/16
SEO対策h1タグとは?初心者向けにSEO効果と正しい使い方を徹底解説2026/01/162026/01/16
-
 SEO対策YMYLとは?対象ジャンルやSEOを成功させるためのポイントを解説2025/12/19
SEO対策YMYLとは?対象ジャンルやSEOを成功させるためのポイントを解説2025/12/192025/12/19
-
 SEO対策キーワード選定のやり方・コツを初心者向けに徹底解説2025/11/20
SEO対策キーワード選定のやり方・コツを初心者向けに徹底解説2025/11/202025/11/20
-
 SEO対策クリニックのSEO対策ガイド│キーワード設計から対策方法まで徹底解説2025/11/14
SEO対策クリニックのSEO対策ガイド│キーワード設計から対策方法まで徹底解説2025/11/142025/11/14
-
 SEO対策ページの表示速度はSEOに影響する?計測方法と10の改善方法を解説2025/11/05
SEO対策ページの表示速度はSEOに影響する?計測方法と10の改善方法を解説2025/11/052025/11/05