クロールバジェットとは?定義と上限・最適化の方法を解説

クロールバジェットとは、Googleの検索エンジンが一定期間に1つのWebサイトをクロールできる上限量の事です。大規模サイトではクロールバジェットの影響で十分にクロールされず、インデックス登録や検索結果への反映が遅れる原因となるため、最適化が重要になります。今回はクロールバジェットの仕組みから最適化の方法を解説します。
クロールバジェットとは?意味と定義
「クロールバジェット」とは、Googleの検索エンジン(クローラー/Googlebot)が、1つのWebサイトを一定期間にクロールできる上限量を指す言葉です。
Googleは世界中の膨大なWebサイトをクロールしていますが、リソースには限りがあるため、1つのサイトを無制限にクロールすることはできません。
そのため、Googleは効率的にクロールを行うために、各サイトごとにクロール量を調整し割り当てています。この仕組みを「クロールバジェット」と呼びます。
Webページはクロールされて初めてインデックスの対象となるため、クロールされなければ検索結果に表示されません。Webサイト運営者は、クロールバジェットを無駄に消費せず、効率的に使えるよう最適化する必要があります。
クロールバジェットの影響を受けやすいサイト
クロールバジェットはすべてのWebサイトに関係しますが、特に影響を受けやすいのは以下のようなWebサイトです。
- 大規模サイト
-
数十万〜数百万ページ規模のECサイトや不動産情報サイトなど、ページ数が非常に多いサイト。ページ数が膨大な場合、割り当てられたクロールバジェットの範囲内ではすべてのページを巡回しきれず、一部のページがクロールされない可能性があります。
- 更新頻度の高いサイト
-
ニュースサイトやブログメディアのように、毎日大量に新規ページが追加されるサイト。次々と新しいページが公開されるため、クロールバジェットが不足すると新規ページのクロールが遅れ、記事が検索結果に反映されるまで時間がかかることがあります。
一方で、10ページ〜1,000ページ規模の一般的なコーポレートサイトやブログであれば、通常はクロールバジェットが問題になることはほとんどありません。
そのため、1,000ページ以下の中小規模サイトや個人ブログでは「クロールバジェットを増やすこと」よりも、コンテンツの質を高めて検索エンジンに価値を認めてもらうことの方が重要です。
クロールバジェットが決定する仕組み
クロールバジェットは大きく分けて 「クロール能力の上限」(どれだけクロールできるか) と 「クロールの必要性」(どのURLを優先してクロールするか) の2つの仕組みで決まります。
クロール能力の上限
Googleは、Googlebotがサイトをクロールする際にサーバーへ負担をかけないよう「クロール能力の上限」を設けています。これは、同時接続数やアクセス間隔を調整する仕組みです。
クロール能力の上限は、主に以下のような要因で変動します。
- サイトの応答状態
-
サイトが速く安定していれば、Googlebotは「もっとクロールしても大丈夫」と判断し頻度を上げます。逆に、表示が重かったりサーバーエラーが多いと、負荷を避けるために頻度を下げます。
- Google側のクロール上限
-
Googleのリソースにも限りがあるため、他サイトとのバランスを考慮しながらクロール頻度が割り当てられます。
このようにクロール能力の上限は、サイトの技術的な状態とGoogle側のリソース状況の両方から影響を受けて決まります。したがって、サイトの表示速度やサーバーの安定性を改善することが、クロールバジェットを確保する最も基本的な対策といえます。
クロールの必要性
クロールの必要性とは、Googleが「どのページを優先してクロールするか」を決める基準のことです。主に次の3つが判断材料になります。
- 人気度
-
アクセス数が多いページや、更新が頻繁なニュース記事、被リンクを多く集めているページは、検索結果に最新情報を反映するため優先的にクロールされます。
- 古さ
-
ページ内容と検索結果に差が出ないよう、Googleは定期的に再クロールを行います。更新が多いページは頻度が高く、変化の少ないページは頻度が低くなります。
- 検出されたURL群
-
Googlebotは見つけたURLを基本すべてクロールしようとしますが、重複ページや不要なURLが多いとクロールが分散し、重要なページが後回しになることがあります。
つまり、「人気度」「古さ」「検出されたURL群」を考慮し、クロールの必要性が高いWebサイトほどクロールバジェットが多く割り当てられる仕組みになっています。
クロールバジェットを最適化する方法
前述した通り、クロールバジェットは「どれだけクロールできるか」と「どのページを優先するか」で決まります。
不要なURLが多かったり、サーバーが遅かったりすると重要なページにリソースが回らない恐れがあります。ここからは、限られたクロールバジェットを有効に活用するための方法を解説します。
クロールバジェットを最適化する方法は次の7つです。
重複コンテンツを統合する
robots.txtで不要なページのクロールを制限する
完全に削除されたページは404もしくは410を返すようにする
soft 404エラーを削除する
リダイレクトチェーンを避ける
XMLサイトマップを最新の状態にする
ページの表示速度を改善する
それぞれ詳しく解説します。
重複コンテンツを統合する
Webサイト内に重複ページが多いと、Googlebotは同じような内容のURLを何度もクロールしてしまい、クロールバジェットが無駄に消費されます。
その結果、本来インデックスさせたい重要ページが後回しにされる可能性があるため、重複コンテンツを統合し、検索エンジンに「どのページを正規ページとして評価してほしいか」を伝えることが大切です。
重複ページを統合するには以下の方法があります。
- canonicalタグの設定
-
カラー違いの商品ページなど、同じ内容を持つ複数のURLがある場合、canonicalタグで正規URLを指定します。
- 301リダイレクトの設定
-
内容が完全に重複するページは、301リダイレクトを使って1つのURLに統合する。
robots.txtで不要なページのクロールを制限する
クロールを最適化する方法の2つ目は「robots.txtで不要なページのクロールを制限する」ことです。
Googlebot はサイト内で見つけたURLを基本的にすべてクロールしようとします。その中には、検索結果に表示する必要のないページや、クロールしても価値のないページも含まれまるため、場合によってはクロールバジェットを消費する原因になります。そこで役立つのがrobots.txtです。
robots.txtは、特定のディレクトリやURLパターンを指定し、Googleに「このページはクロールしなくてよい」と指示することができます。
サイト内検索結果ページ
カートや購入完了ページ
フィルタや並び替えで生成されるパラメータ付きURL
管理画面やログインページ
完全に削除されたページは404もしくは410を返すようにする
クロールを最適化する方法の3つ目は、削除済みのページに対して404または410のステータスコードを返すようにすることです。
削除したページや不要なページにいつまでもアクセスできる状態を残してしまうと、Googleのクローラーは何度も巡回し続けるため、クロールバジェットを浪費します。
そこで、削除したページには必ず404 や410 を返すようにすることで、Googleに「もう見る必要はない」と伝えることができます。つまり、削除済みのページに対して、404や410を正しく設定することは「クロール最適化」に繋がり、クロールバジェットの有効活用になります。
404(Not Found) は「ページが見つかりません。存在しない可能性があります」という意味です。
410(Gone) は「このページは削除されていて、もう戻ってくることはありません」という意味です。
soft 404エラーを削除する
クロールを最適化する方法の4つ目は、soft 404エラーを削除することです。
前述した通り、「ページが存在しない」場合には404や410のステータスコードを返すべきですが、実際には200(OK)などの「正常にページがありますよ」というコードを返してしまっている状態をSoft 404と呼びます。
例えば、ページの中身が「お探しのページは見つかりません」と表示されているのに、裏側のステータスコードが200になっている場合がSoft 404にあたります。Soft 404を放置すると、Googlebotは「中身が空っぽのページ」に何度もアクセスし続けるため、クロールバジェットが無駄に消費されてしまいます。
Soft 404はGoogleサーチコンソールのインデックスレポートから確認できるため、発生していたらすぐに対処しましょう。
リダイレクトチェーンを避ける
クロールを最適化する方法の5つ目は、リダイレクトチェーンを避けることです。
「リダイレクトチェーン」とは、リダイレクト元と最終的なリダイレクト先の間に、複数のリダイレクトが設定されている状態です。
Googleのジョン・ミュラー氏はリダイレクトチェーンがあると、クローラーの負担が増加するため、5回目以降は次回のクローリングに回されると発言しています。
If there's one thing to remember, it's that we follow redirects up to five times. If the redirects exceed five, they will be deferred to the next crawl cycle.
https://www.youtube.com/watch?v=SUaPrCV-0jM
多すぎるリダイレクトチェーンはクロールバジェットの無駄使いとなるため、改善するようにしましょう。
XMLサイトマップを最新の状態にする
クロールを最適化する方法の6つ目は、XMLサイトマップを最新の状態にすることです。
XMLサイトマップとは、Webサイト内のページ構造を検索エンジンに伝えるための専用ファイルのことです。
Googleのクローラーは定期的にXMLサイトマップを読み込み、記載されたURLをクロール対象として確認します。そのため、新しいページを追加した場合や古いページを削除した場合には、必ずXMLサイトマップを更新しておくことが大切です。
常にXMLサイトマップを最新の状態にしておけば、Googleは不要なページを無駄にクロールすることなく、新規ページや優先度の高いページを効率よくクロールすることができます。つまり、クロールバジェットの無駄を防ぐことにつながるという訳です。
ページの表示速度を改善する
クロールを最適化する方法の7つ目は、ページの表示速度を改善することです。
ページの読み込みが遅いと、Googleのクローラーは1ページの情報を取得するのに時間がかかり、その分だけ巡回できるページ数が減ってしまいます。一方で、ページの表示速度を改善すれば、クローラーは短時間でより多くのページを処理できるため、クロール効率が大幅に高まります。
不要なスクリプトの削除や画像の最適化、キャッシュの活用などの施策によってレンダリング速度を上げることで、クロールバジェットを有効に活用できるようになります。
クロールバジェットに悪影響を及ぼすページの種類
クロールバジェットは限りがあるため、不要なページにクローラーが回ってしまうと、本来クロールすべき重要なページがおろそかになります。
特に次のようなページはクロールバジェットを無駄に浪費するため注意が必要です。
| 悪影響を及ぼすページ | 内容 |
|---|---|
| ファセットナビゲーション/セッションID | 並べ替え・フィルタリング・セッションID付きURLなど、同じ内容を繰り返し生成するURL。 |
| 重複コンテンツ | 同じ内容を複数URLで提供している状態。 GoogleはどのURLを評価するか判断に迷う。 |
| Soft 404ページ | 実際には存在しないのに200コードを返しているページ。 クロールリソースが消費される。 |
| ハッキングされたページ | 不正アクセスによって生成されたページ。 クロール効率だけでなくサイト全体の評価にも悪影響がある。 |
| 無限のスペース/プロキシ | 内部検索やカレンダーなどで無限にURLが生成されるケース。 クローラーが際限なくクロールしようとする。 |
| 低品質/スパムコンテンツ | 内容が薄いページや自動生成されたスパムページ。 品質の低いページはクロール頻度が低下します。 |
| 特定の機能ページ | ユーザー行動が前提であり、検索に出す必要がないページ。 クロールされても意味がありません。 |
上記のように「重複・低品質・エラー」系のページはクロールのリソースを無駄に使うため、クロールバジェットに悪影響を及ぼします。
こうしたページを正しく整理・制御することが、クロール最適化につながります。
クロール頻度の確認方法
実際に自社で運営するサイトがいつクロールされたのか、どのくらいの頻度でクロールされているのかをGoogleサーチコンソールで確認してみましょう。
Googleサーチコンソールにログインする
画面左のメニュー「設定」をクリックする
「クロールの統計情報」の「レポートを開く」をクリックする
以下のような画面が表示され、過去90日間に行われたクロールリクエストの合計数を、日別に確認できます。
グラフで表示されるため、クロール頻度の変動を視覚的に確認することも可能です。
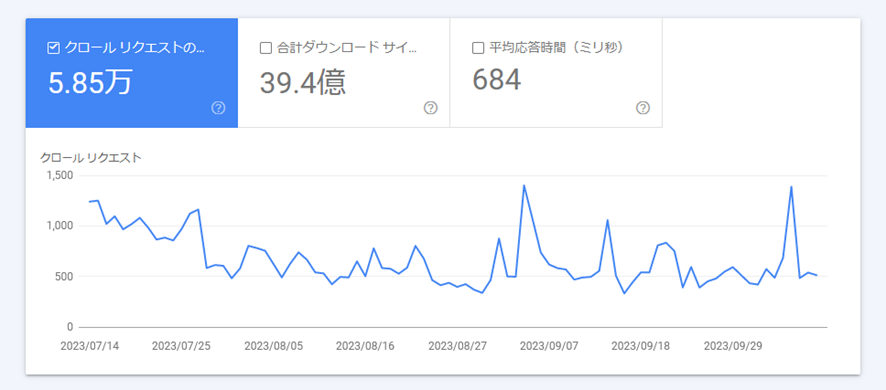
上記画像の例では、約3ヵ月で5.85万回クロールされている事が分かります。
最新のクロール日を確認する手順
クロール頻度を確認したら、次に最新のクロール日を確認してみましょう。
Googleサーチコンソールにログインする
画面左のメニュー「URL検索」をクリック
画面上部の検索窓に確認したいURLを入力
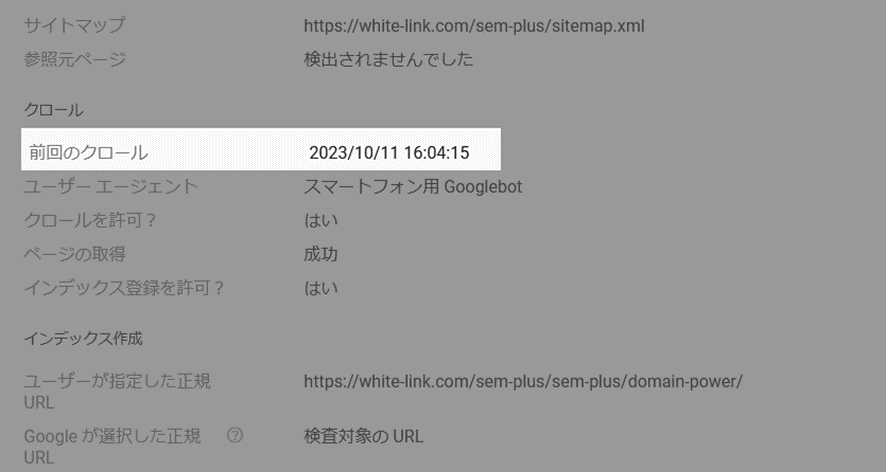
画面上に表示された「ページのインデックス登録」をクリック
「前回のクロール」の欄に、最後にクロールされた日時が表示されるので確認する
クロールバジェットに関するよくある質問
クロールバジェットの上限を教えてください。
クロールバジェットに明確な「数値の上限」は公開されていません。
Googleはサイトごとに「サーバーが処理できる負荷」と「そのサイトに対する需要」を組み合わせて、クロールできる量を動的に決めています。
つまりクロールバジェットの上限は固定ではなく、サイトの規模・人気・更新頻度・サーバー応答の速さなどによって変動すると言うことです。
nofollowはクロールバジェットに影響しますか?
nofollow属性は、基本的にクロールバジェットの節約にはならないとGoogleは説明しています。
nofollowリンクがあると、Googleはそのリンク先を「評価のためにリンクをたどらない」扱いにしますが、必ずしも「クロールしない」とは限りません。
Googleは別の経路(nofollowのない他のページからのリンクや外部サイトからのリンク)からURLを見つければ、普通にクロール対象とします。
参考ページ:検索セントラル:nofollow ルールはクロールの割り当てに影響しますか?
noindexはクロールバジェットに影響しますか?
noindexは、直接クロールバジェットを節約する効果はありません。
なぜなら、Googleはnoindexが付いているページもまずはクロールしないと、その指示を確認できないからです。
ただし、Googleはnoindexが付与されたページを存在しないページとして扱うとも公言しているため、中長期的に見るとクロール対象から外れる可能性があります。
クロール頻度はSEOのランキングに影響しますか?
クロール頻度そのものはSEOのランキング要因ではありません。
Googleは公式に「クロールの回数や速度が検索順位に直接影響することはない」と明言しています。
ただし、クロール頻度が高いサイトは、新しく公開したページや更新内容が早くインデックスされやすくなるため、間接的にはSEOに良い影響をもたらします。
まとめ
今回は、クロールバジェットの意味と定義、決定する仕組み、影響を受けるサイトのタイプ、最適化する方法、クロール頻度の確認方法について解説しました。
小規模・中規模のWebサイトではクロールバジェットの影響はほとんどないため、クロールバジェットを意識する必要はありません。
一方で、大規模なサイトやニュースサイトのように更新頻度の高いWebサイトの場合は、クロールバジェットの影響を受けやすくなります。不要なページや重複コンテンツにクロールが割かれてしまうと、本来インデックスさせたい重要なページが後回しになり、検索結果への反映が遅れるリスクがあります。
そのため、本記事で紹介したクロールバジェットを効率的に使えるよう最適化することが重要です。クロールバジェットを正しく理解し、無駄を減らす取り組みを行うことで、大規模サイトであっても安定して検索結果にページを反映させることができ、SEO全体の成果につながります。
なお、社内のリソース不足やノウハウ不足でクロールバジェットを最適化するための施策に十分に取り組めない場合は、専門的な知識を持つ外部パートナーを活用することも有効です。
弊社では、サイト規模や業態に応じたクロール最適化の診断・改善支援を行っており、不要なクロールの削減から重要ページのインデックス促進までサポートいたします。
大規模サイトや更新頻度の高いメディアを運営されている方は、ぜひお気軽にご相談ください。

この記事を書いたライター

SEMを軸にSEOの施策を行うオルグロー内の一部署。 サイト構築段階からのSEO要件のチェックやコンテンツ作成やサイト設計までを一貫して行う。社内でもひときわ豊富な知見を有する。またSEO歴15年超のノウハウをSEOサービスに反映し、3,000社を超える個人事業主から中堅企業までの幅広い顧客層に向けてビジネス規模にあった施策を提供し続けている。
ぜひ、読んで欲しい記事
-
 SEO対策SEOの外部対策とは?具体的なやり方を徹底解説2026/06/22
SEO対策SEOの外部対策とは?具体的なやり方を徹底解説2026/06/222026/06/22
-
 SEO対策サイトリニューアルのSEO対策12選|順位が下がる原因と影響を解説2026/06/22
SEO対策サイトリニューアルのSEO対策12選|順位が下がる原因と影響を解説2026/06/222026/06/22
-
 SEO対策LLMOとは?自分で対策するやり方と仕組みを解説2026/06/18
SEO対策LLMOとは?自分で対策するやり方と仕組みを解説2026/06/182026/06/18
-
 SEO対策ECサイトのSEOに強い会社おすすめ7社|強みや特徴を一覧で紹介2026/06/11
SEO対策ECサイトのSEOに強い会社おすすめ7社|強みや特徴を一覧で紹介2026/06/112026/06/11
-
 SEO対策llms.txtとは?書き方と設置手順・意味がないと言われる理由を解説2026/06/16
SEO対策llms.txtとは?書き方と設置手順・意味がないと言われる理由を解説2026/06/162026/06/16
-
 SEO対策サイテーションとは?やり方やSEO・MEO・LLMOでの重要性を解説2026/05/28
SEO対策サイテーションとは?やり方やSEO・MEO・LLMOでの重要性を解説2026/05/282026/05/28