「検出-インデックス未登録」の意味とは?表示される原因と解決策を解説

「検出-インデックス未登録」とはGoogleクローラーがURLを発見しているが、ページをクロールしていない状態を示すステータスです。サーチコンソールのインデックスレポート内でこのステータスが表示された場合、「インデックスされていない」事を意味します。今回は「検出-インデックス未登録」の原因と解決策について解説します。

「検出 - インデックス未登録」とは
Googleサーチコンソールに表示される「検出 - インデックス未登録」とは、インデックスされていない理由を示すステータスの一つで、GoogleのクローラーがページのURLは発見しているものの、まだクロールを開始していない状態を指します。
Googleのクローラーは、「URLの発見」→「クロール」→「レンダリング」→「インデックス登録」という流れで処理を進めますが、「検出 - インデックス未登録」は最初の「URLの発見」で止まっている状態です。
「検出 - インデックス未登録」は一時的なサーバー負荷やクロールバジェットの制限、またはページの品質が低いと判断されていることなどが原因で発生します。
時間が経てば自動的にクロールされて解消されることもありますが、数週間〜数ヶ月経ってもインデックスされない場合は、ページの品質や内部リンク構造などに問題がある可能性が高いため、改善施策を行う必要があります。

「検出 - インデックス未登録」と「クロール済み - インデックス未登録」の違い
Googleサーチコンソールで確認できるインデックス未登録のステータスに、「検出 - インデックス未登録」とよく似た「クロール済み - インデックス未登録」があります。
「クロール済み - インデックス未登録」は、Googleがそのページを実際にクロールしたにも関わらず、インデックスに登録しなかった状態です。
つまり、Googleはそのページの内容を見た上で、「検索結果に表示する価値がない」と判断したということです。名前は似ていますが、発生する原因や対処方法が異なるため混同しないようにしておきましょう。
| ステータス名 | 詳細 | 主な原因 |
|---|---|---|
| 検出 - インデックス未登録 | GoogleがURLを発見したが、まだクロールしていない状態 | サーバー負荷 ・クロールバジェットの制限、品質の問題など |
| クロール済み - インデックス未登録 | GoogleがURLをクロール済みだが、インデックスしなかった状態 | 品質の問題・重複コンテンツなど |
▼「クロール済み - インデックス未登録」については、別の記事で詳しく解説しています。
「検出 – インデックス未登録」になる原因
「検出 - インデックス未登録」が表示される原因は、次の4つです。
品質の問題
サーバーの問題(過負荷など技術的な問題)
重要なページと見なされない
クロール待ちの状態
GoogleのMartin Splitt氏は、「検出 - インデックス未登録」になる原因をYouTubeでサーバーの問題と品質の問題をあげていますが、それ以外にも「重要なページと見なされない」場合や、「クロール待ちの状態」も「検出 - インデックス未登録」の原因になります。
それぞれ詳しく解説します。
原因①:品質の問題
「検出 - インデックス未登録」の主な原因として最も多いのは、ページやサイト全体の品質に問題があるケースです。
他サイトの情報を寄せ集めただけのコンテンツや、独自性が低く内容が薄いページなど、Google検索を利用するユーザーにとって有益ではない・価値が低いと判断されるページは、インデックスの優先度が低くなります。
このようなページはGoogleから「現時点でインデックスする必要がない」と判断され、「検出 - インデックス未登録」になります。
GoogleのMartin Splitt氏は、「低品質または内容の薄いコンテンツが多い場合、Googleはそれらのページをインデックスから除外し「検出済み」のままに留めることがある。Googlebotはページの存在は知っているが、処理しないことを選択している」と述べています。
「クロール済み - インデックス未登録」に表示されているURLのパターンと、「検出 - インデックス未登録」に表示されているURLのパターンが類似している場合は、URLのパターンから低品質コンテンツであるため、クロールする必要がないと判断されている可能性が高いです。
原因②:サーバーの問題(過負荷など技術的な問題)
100万ページを超える大規模サイトや、サーバーの性能や応答速度に問題があるWebサイトでは、「検出 - インデックス未登録」が発生する可能性があります。
Googleのクローラーがページを検出しても、クロールの実行を保留・回避せざるを得ない状況があるためです。
500エラー
500エラーとは、Googlebotがページにアクセスしようとした際に、サーバー内部で処理が失敗し、エラーとして返される状態を指します。
例えば、商品ページにアクセスしようとしたタイミングで、サーバー側で一時的な不具合が起きて「Internal Server Error(500)」が返されると、GoogleはそのURLのクロールを控えるようになります。
これが何度も繰り返されると、Google側ではそのURLを不安定とみなし、クロールの優先順位を下げたり、一定期間クロールを見送る判断をすることがあります。その結果、「検出 - インデックス未登録」が発生します。
頻繁に遅延や500エラーが発生しているなら、サーバー性能の強化やサーバー設定の見直しを行いましょう。
クロールバジェット
クロールバジェットとは、Googlebotが特定のサイトに対して割り当てる「1日にクロールできるURLの数」や「リソースの上限」のようなものです。
例えば、100万ページ以上あるような大規模なECサイトの場合、XMLサイトマップを送信してURLを伝えたとしても一度に100万ページをクロールするわけではありません。
Googlebotはサイトに過剰な負荷をかけないよう、ページの重要度や更新頻度、内部リンクの構造などを判断材料にして、クロールの順番を決めます。
その結果、優先順位が低いと判断されたページはクロール待ちの状態が続き、「検出 - インデックス未登録」が表示されます。
GoogleのMartin Splitt氏は公式動画で、例として「一度に1000件の新商品ページを追加した場合、Googlebotはすべてを即座にクロールする代わりに、過去のクロールでサーバーが10件以上同時に処理すると遅くなるとわかっていれば、数時間かけて10件ずつ処理するように間引く」ことがあると説明しています。
原因③:重要なページであると見なされていない
重複コンテンツや深い階層にあるページ・内部リンクがないページは、Googleから重要なページではないと判断されクロールの対象から外されることがあります。
重複コンテンツ
重複コンテンツとは、コンテンツの内容が同じであるにも関わらず、URLの異なるページが存在している状態のことを指します。
Googleからすると、内容が同じぺージや似たぺージを検索結果に表示させる意味がないため、似ているページはクロール対象から外れ「クロール済み - インデックス未登録」になります。
Mueller氏は、「パラメータ違い・大文字小文字違いのURLが大量に存在すると、Googleはそれらを重複とみなし「類似ページは既にあるからすべてクロールする必要はない」と判断してクロールを抑制する」と説明しています。
【参考】https://www.youtube.com/watch?v=6Lu2F_y54fg&t=677s(11分17秒~)
深い階層にあるページ・内部リンクがないページ
内部リンクが設定されていない孤立したページやサイトマップ以外から辿れないページ、階層が深いページは「検出 - インデックス未登録」になることがあります。
その理由は、URLがクローラーに発見されても、サイト内で優先度が低いと判断されるためです。
特に、他ページからのリンクが一切ない「孤立したページ」は、Googleにとってもユーザーにとっても価値の低いコンテンツと見なされやすくインデックス登録されにくくなります。
原因④:クロール待ちの状態
Googleがクロールできる数は限られています。そのため、新規に公開するページ数が多い場合など、Googleのクローラーが他のページでクロールで忙しい場合は、クロール待ちのURLが発生し、「検出 - インデックス未登録」に表示されます。
つまり、「まだ手が回っていないだけ」のケースです。
「検出 - インデックス未登録」は、GoogleがそのURLを「クロールの順番待ちリスト」に入れている状態の場合もあり、必ずしもエラーではありません。
また、Googleは「Webサイト上の全コンテンツをインデックスしない」のが通常であり、多くのサイトでいくつかの未インデックスページが存在するのは珍しくないと公式でも発表しています。
「検出 – インデックス未登録」の原因を特定する方法
「検出 – インデックス未登録」の原因を特定するためには、以下の手順で問題を切り分けていきましょう。

サーチコンソールまたはサーバーログで「500エラー」が発生していた?
→ はい:サーバーの問題の可能性が高い
→ いいえ:②へ進む最近、大量のページを一度に公開・更新した?
→ はい:クロールバジェットによる待機状態
→ いいえ:③へ進む該当ページは深い階層にある、または内部リンクが少ない?
→ はい:サイト内で重要でないと判断された可能性があり
→ いいえ:④へ進むコンテンツの質が低い(薄い・重複・寄せ集めなど)
→ はい:品質の問題
→ いいえ:その他の問題
このフロー図に沿って確認して行くことで、原因の特定に繋がりやすくなります。
「検出 – インデックス未登録」の解決方法
「検出 - インデックス未登録」の解決方法は、次の3点です。
URL検査ツールを使い、インデックス登録リクエストを送信する
ページの品質を改善する
サーバーの見直しを行う
原因に合わせて解決方法を解説します。
URL検査ツールを使い、インデックス登録リクエストを送信する
Googleサーチコンソールの「URL検査ツール」は、特定のURLがGoogleにどのように認識されているかを確認したり、手動でインデックス登録をリクエストできる機能です。
「検出 - インデックス未登録」の状態にあるURLも、URL検査ツールからインデックス登録リクエストを行うことで再クロールを促すことができます。
Googleサーチコンソールにログイン
上部の検索窓に該当URLを入力し「Enter」キーを押す
「インデックス登録をリクエスト」をクリックして完了
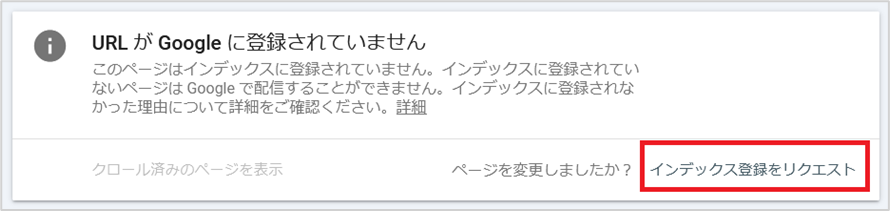
クロールの順番待ちであれば、インデックス登録される可能性が高いですが、インデックス登録リクエストを行ったにも関わらず、クロールされない場合やインデックスされない場合は、ページの品質に問題がある可能性が高いと言えます。
▼ URL検査ツールについては別の記事で詳しく解説しています。
ページの品質を改善する
他サイトと似たような独自性の低いページやAIを使って量産したページ、内容の薄いページなど、E-E-A-Tが低くユーザーの検索ニーズを満たさないページは、クロール対象とならないため、ぺージの品質を改善する必要があります。
「検出 - インデックス未登録」が大量に発生するケースで多いのは、データベース型のWebサイトの一覧ページや詳細ページが、自動で大量に生成されている場合です。
例えば、不動産のサイトや求人のサイトでは、条件ごとに絞り込みができる一覧ページが、何千、何万と自動で生成され、その下層にある詳細ページもテンプレート化されていることが一般的です。
このようなページが生成される際に、次の要因に該当する場合は、Googleから「価値が低い」と判断され「検出 - インデックス未登録」が発生しやすくなります。
同じテンプレートで構成されたページが大量に存在し、コンテンツの差分がほとんどない
一覧ページに掲載されている情報(メインコンテンツ)が極端に少ない
詳細ページの説明文や画像などの独自情報が不足している
地域名やカテゴリ名を変えただけのページが大量生成されている
そのため、一覧ページや詳細ぺージのテンプレートから見直しを行ったり、システムの改修を行い表示させる情報を増やすなど、根本的にページの品質を改善する必要があります。
記事ページやサービスページの場合は、ページ単体の評価を改善するためにリライトしたりワイヤフレームの見直しを行い、品質を改善しましょう。
サーバーの見直しを行う
サーチコンソールの「クロールの統計情報」を見ると、過去90日間のクロール活動に関する詳細なデータが表示され、「1日あたりのクロール済みページ数」「ページ取得にかかった平均応答時間」「ダウンロードに失敗した回数」などを確認できます。
500エラーが一定以上の頻度で発生していたり、クロール数が急激に落ち込んでいたり、応答時間が長期にわたって高止まりしている場合、Googleがクロールの負荷を軽減しようとしてクロールを控えている可能性があります。
このような状態が続くと、Googlebotがページを検出してもクロールを実行せず、「検出 - インデックス未登録」の状態になるURLが増えていきます。
Googlebot に「過負荷の信号」を送らないようにするために、次のようなサーバー環境やサイトパフォーマンスの見直しを行います。
サーバーのスペックを見直し、リソースの不足がないか確認する
サイト全体のページ表示速度を高速化する
Googlebot によるアクセスが集中する時間帯のサーバー負荷状況を監視し、スケーリング対応を行う
5xx系のエラーが出ているページのログを確認し、原因となるコードやリクエストを修正する
クロールの統計情報については、別の記事で詳しく解説しています。
大規模サイトで発生する「検出 – インデックス未登録」への対策
大規模サイトでは次の2点に注意しておくことで、「検出 - インデックス未登録」の発生を防ぐことができます。
品質の低いページや重複ページの発生を防いでおく
内部リンクの見直しを行う
それぞれ詳しく解説します。
品質の低いページや重複ページの発生を防いでおく
大規模サイトの場合はクロールバジェットの影響を受けやすいため、あらかじめ品質の低いページや重複コンテンツが増えないように管理しておくことが、「検出 - インデックス未登録」の発生を防ぐ上で重要です。
インデックスさせたいページを優先的にクロールしてもらうようにするために、低品質なページや重複コンテンツにはnoindexタグを付与するなど、対策を行っておきましょう。
Googleは、noindexが付与されたページについてはインデックス対象から除外し、時間の経過とともにクロール頻度を減らす傾向があります。
つまり、クローラーの順番待ちによる「検出 - インデックス未登録」を減らすことができるというわけです。
noindexを付与する対象となるURLは、次のようなページです。
情報が古くなったコンテンツ
Webサイト内の検索ボックスによって生成されたページ
並び替えや絞り込みによって発生した重複したコンテンツ
自動生成コンテンツ
内容の薄いユーザー生成コンテンツ
内部リンクの見直しを行う
前述した通り、他のページからリンクされていない「孤立ページ」は重要ではないページと判断され、「検出 - インデックス未登録」になる場合があります。
また、リンクがあったとしても、トップページやカテゴリページから何クリックも必要な“深い階層”に埋もれているURLや、サイトマップ経由でしか到達できないようなURLでは、Googleはそのページを「サイト内で重要ではない」と判断する可能性があります。
この問題を解消するためには、次のような対策が有効です。
トップページやカテゴリページなど、サイト内で主要なページから直接リンクを設置する
関連する記事や商品ページと内部リンクを繋ぐ
パンくずリストを設置し、階層構造を明確にする
サイドバーやフッターによく見られるページとして掲載する
サイト内にあるすべてのページに2~3クリックで辿り着けるサイト構造にする
内部リンクの最適化は、「検出 - インデックス未登録」の解消だけではなくユーザビリティの改善にも繋がるため、Webサイトに遷移したユーザーにとって使いやすいリンク動線になるようにしておきましょう。
なお、ahrefsのサイト監査機能を利用すれば、Webサイト内で孤立しているページを簡単に見つけることができます。
「検出 – インデックス未登録」に関するよくある質問
XMLサイトマップを送信すれば「検出 - インデックス未登録」は改善しますか?
結論から言うと、XMLサイトマップを送信しても「検出 – インデックス未登録」は改善しません。
繰り返しになりますが、「検出 – インデックス未登録」は、GoogleがそのURLの存在をすでに把握していながら、何らかの理由でクロールを開始していない状態を示しています。
XMLサイトマップは、「サイト内にこういうURLがある」とGoogleに知らせる役割しか持ちません。 「検出 – インデックス未登録」に表示されているページはすでにURLが検出済みなので、XMLサイトマップを再送しても「もう知っているURL」として扱われるだけで、状況は変わらないということです。
「検出 - インデックス未登録」に表示されるURLは robots.txt でブロックされている可能性がありますか?
「検出 – インデックス未登録」というステータスは、robots.txtによるブロックが原因である場合は表示されません。
robots.txtでブロックされている場合、サーチコンソールには「robots.txt によりブロックされました」という別ステータスで表示されます。

大量の「検出 - インデックス未登録」が出ていても気にしなくていいですか?
発生している原因によります。ページの内容が低品質なことが原因で、インデックスさせたいページが「検出 – インデックス未登録」になっている場合は、Webサイトの流入数やサイト全体の検索順位に大きく影響するので改善が必要です。
特に、データベース型の大規模サイトでこのステータスが大量に出ている場合、サイト構造や一覧ページ・詳細ページのテンプレートに問題がある可能性があります。
SEO対策に影響するため、早急に原因を突き止めて改善策を実行しましょう。
まとめ
「検出 - インデックス未登録」は、GoogleがURLを認識しているにも関わらず、クロールが行われていない状態を示しています。ページの品質、サーバーの応答速度、内部リンクの構造など多くの要因が関係するため、原因を正確に特定するためには専門的な知識や経験が必要になります。
大規模サイトで「検出 - インデックス未登録」が大量に発生し、主要なページが中々インデックスされていない場合や、サイト全体の検索順位が低い場合などは早急な対応が必要です。
もし社内で解決できない場合は、ぜひ弊社までご相談くださいませ。大規模サイトや、データベース型のSEO支援を行ってきた経験を元に的確なアドバイスを行います。
この記事を書いたライター

SEMを軸にSEOの施策を行うオルグロー内の一部署。 サイト構築段階からのSEO要件のチェックやコンテンツ作成やサイト設計までを一貫して行う。社内でもひときわ豊富な知見を有する。またSEO歴15年超のノウハウをSEOサービスに反映し、3,000社を超える個人事業主から中堅企業までの幅広い顧客層に向けてビジネス規模にあった施策を提供し続けている。
ぜひ、読んで欲しい記事
-
 SEO対策リッチリザルトとは?種類と表示のさせ方・表示されない原因を解説2026/02/03
SEO対策リッチリザルトとは?種類と表示のさせ方・表示されない原因を解説2026/02/032026/02/03
-
 SEO対策【2026最新版】検索順位チェックツールおすすめ10選!無料・有料それぞれ紹介2026/02/03
SEO対策【2026最新版】検索順位チェックツールおすすめ10選!無料・有料それぞれ紹介2026/02/032026/02/03
-
 SEO対策Googleクローラーとは?仕組みと申請方法・巡回頻度を高めるやり方2026/02/02
SEO対策Googleクローラーとは?仕組みと申請方法・巡回頻度を高めるやり方2026/02/022026/02/02
-
 SEO対策h1タグとは?初心者向けにSEO効果と正しい使い方を徹底解説2026/01/16
SEO対策h1タグとは?初心者向けにSEO効果と正しい使い方を徹底解説2026/01/162026/01/16
-
 SEO対策YMYLとは?対象ジャンルやSEOを成功させるためのポイントを解説2025/12/19
SEO対策YMYLとは?対象ジャンルやSEOを成功させるためのポイントを解説2025/12/192025/12/19
-
 SEO対策キーワード選定のやり方・コツを初心者向けに徹底解説2025/11/20
SEO対策キーワード選定のやり方・コツを初心者向けに徹底解説2025/11/202025/11/20