Googleクローラーとは?仕組みと申請方法・巡回頻度を高めるやり方

Googleのクローラーとは、世界中のWebページを自動で巡回し、ページの内容を取得して検索結果に反映するためのロボットです。リンクを辿って新しいURLを見つけ、HTMLや画像、CSS、JavaScriptなどを読み取り、検索データベースに保存します。本記事では、Googleクローラーの仕組みや申請方法を解説します。
Googleクローラーとは?
Googleクローラー(Google bot)とは、自動で世界中のWebサイトを巡回しながら情報を収集し、検索データベース(インデックス)に登録するプログラムのことです。
Googleクローラーは、Webサイトを定期的に巡回して、Webサイトの「HTML」「CSS」「JavaScript」などのコードを解析し、ページ上のテキスト、画像、動画、リンク、メタデータなどを取得します。
Googleはクローラーが取得したこれらの情報を元に、アルゴリズムでランキングを決定し検索結果にWebページを表示させています。つまり、Googleのクローラーとは検索結果に表示されるための「入口」になる存在です。
そのため、SEOでは「クローラーが巡回しやすいサイト構造になっているか」「重要なページが正しくクロール・インデックスされているか」を整えることが、成果を出すための土台になります。
クローラーは這い回るという意味の「crawl」から名称されており、「ボット」や「スパイダー」などと呼ばれることもあります。
Googleクローラーの種類
Googleのクローラーは、目的に応じていくつかの種類があります。代表的なのは、検索結果に表示するためにWebページの情報を収集するGooglebotです。Googlebotには、主に次の2種類があります。
スマートフォン用 Googlebot: モバイル デバイスでユーザーをシミュレートするモバイル クローラー。
検索セントラル:Googlebot
パソコン用 Googlebot: デスクトップでユーザーをシミュレートするデスクトップ クローラー。
GoogleはWebサイトを評価するときに、スマホ版ページの内容を基準にする仕組み「モバイルファーストインデックス」を採用しています。そのためSEOでは、スマートフォン用Googlebotが取得する内容を前提に対策することが重要です。
また、Googleには検索用のGooglebot以外にも、画像・動画・ニュースなど、用途別に情報を取得するクローラーが存在します。
| クローラー名 | 取得対象 | 概要 |
|---|---|---|
| Googlebot-Image | 画像を取得するクローラー | 画像関連のGoogle検索機能や画像に関するサービスで利用される |
| Googlebot-Video | 動画を取得するクローラー | 動画関連のGoogle検索機能や動画に関するサービスで利用される |
| Storebot-Google | 商品情報を取得するクローラ | Google検索のショッピングタブなどGoogleショッピングで利用される |
| Googlebot-News | ニュースに関する情報を取得するクローラー | news.google.comやGoogleニュースアプリなどで利用される |
上記以外にも複数のクローラーがあります。詳しく知りたい方は以下のページをご確認ください。
Googleクローラーが取得するファイル
Googleクローラーは、ページを理解・評価するためにHTMLだけでなく動画や画像など周辺リソースも取得します。クローラが実際に読み取るファイルの一覧は以下になります。
・HTML
クロールの統計情報レポート - Google Search Console ヘルプ
・画像 (Google で取得可能な画像ファイル形式BMP、GIF、JPEG、PNG、WebP、SVG )
・動画 (Google で取得可能な動画ファイル形式: 3GP、3G2、ASF、AVI、DivX、M2V、M3U、M3U8、M4V、MKV、MOV、MP4、MPEG、OGV、QVT、RAM、RM、VOB、WebM、WMV、XAP)
・JavaScript
・CSS
・その他の XML - XML をベースとした RSS、KML などの形式を含まない XML ファイル
・JSON
・シンジケーション - RSS フィードまたは Atom フィード
・音声
・地理データ - KML または他の地理データ。
・その他のファイル形式 - ここに記載されていないその他のファイル形式。
・不明(失敗) - リクエストが失敗した場合、ファイル形式は不明となります。
このように、HTML以外にも多くの情報をクローラーは取得しています。動画や画像などもクローリングしてもらいたい場合は、ファイル形式を間違えないように記述しましょう。
また、上記の中でもSEOを行う上で大きく関係する代表的なものは次のファイルです。
| ファイル | 詳細 |
|---|---|
| HTML / テキスト系ファイル | 本文・見出し・リンク・メタ情報など ※1ファイルあたり最大 15MB まで取得 |
| CSS | レイアウトや見た目の把握のため。HTMLとは別リクエストで取得 |
| JavaScript | レンダリングや動的生成コンテンツの把握のため。HTMLとは別リクエストで取得 |
| 画像ファイル | ページ内で使われる画像。必要に応じて取得 |
| その他 | ページの表示に関わる外部ファイル(CSS/JS経由で読み込まれるフォント、追加画像など) |
Googleクローラーの仕組み(URLの発見からインデックス登録まで)
Googleクローラーが、Webサイトやぺージを発見してからインデックスするまでにどのような過程があるのか説明します。
クローラーがインデックスするまでの基本的な順序は、以下になります。
URLの発見
クロール
レンダリング
インデックス
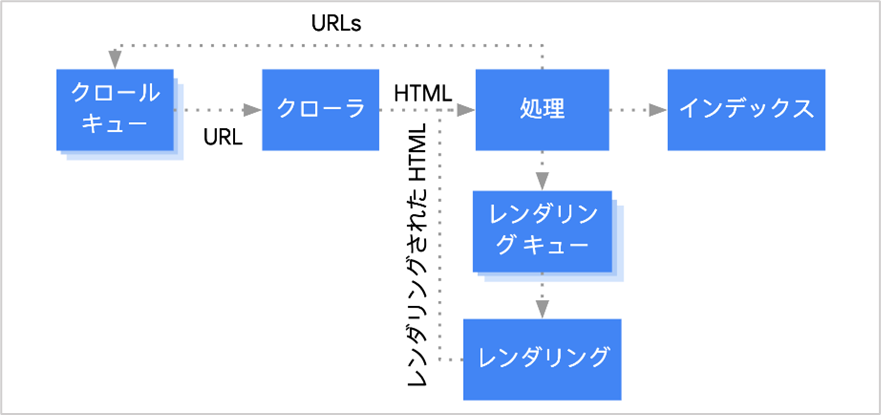
発見されたURLはクローラーによって解析され、ページの内容にガイドライン違反やnoindexの記述がなければ、Googleのデータベースに登録を行い検索結果に表示させます。
それぞれの行程について詳しく説明します。
URLの発見
GoogleのクローラーはWebページ上に設置されたリンクを自動的に辿って新しいURLを発見します。
クローラーが新しいURLを発見すると、そのURLはクロール待ちのリスト(クロールキュー)に追加されます。
そしてGooglebotは、クロールキューにあるURLの中から、状況に応じて優先度の高いURLから順にクロールしていきます。
なお、リンクがないページ(孤立したページ)でも、サイト運営者がGoogleサーチコンソールの「URL検査」からインデックス登録をリクエストしたり、XMLサイトマップを送信することで、GoogleがURLを把握するきっかけを作れます。
サイト内に新しいURLを追加した場合は、すでにクロール対象となっているページから内部リンクを設置しておくことで、クローラーに新しいURLを発見してもらいやすくなります。
クロール
クロールとは、GooglebotがWebページにアクセスして、HTMLや画像・CSSなどの情報を取得することです。
Googleのクローラーは、サイトをクロールする前にrobots.txtを取得・解析し、Googlebotがアクセス可能かを確認します。
robots.txtのDisallowで対象URLのクロールが許可されていない場合、GooglebotはそのURLをクロールせず別のURLの処理に進みます。
クロールが許可されている場合、Googlebot はHTML等を取得し、本文中のリンク(aタグのhref属性)から新しいURLを見つけ、必要に応じてクロールキューへ追加します。
リンク先をクロールさせたくない場合は 「rel="nofollow」 を使いクロールしないように指示します。ただし、Google はnofollowを必ず従う指示ではなく「ヒント」として扱うため、クロールを完全に防げるわけではありません。
レンダリング
レンダリングとは、Googlebotがクロールで取得したHTML/CSS/JavaScriptを読み込み、ブラウザで表示されるのと同じようにページを再現して内容を理解する工程です。
具体的には、Googlebotがソースコードを読み取り、CSSの適用やJavaScriptの実行を通じてDOMを構築し、実際にユーザーがブラウザで見る画面に近い形に変換します。
レンダリングを行うことでGoogleは、JavaScriptで生成される本文・リンク・要素なども把握できるようになります。なお、レンダリング前にページ内の設定(meta robots)も参照され、インデックス登録が禁止されていなければ、レンダリングへ進みます。
noindexタグが設定されている場合は、レンダリングは行われずインデックス登録の対象外となります。
レンダリングされたページがGooglebotからどのように見えているかは、サーチコンソールの「URL検査」→「ライブテスト」 で確認できます。
インデックス
インデックスとは、Googlebotがクロールしたページを、検索データベースに登録する工程のことを言います。インデックス登録されることで、そのページは検索結果に表示されるようになります。
インデックスの段階では、ページのテキストや画像などの情報が整理されます。その過程でデータベース内に類似ページや重複したページが多い場合は、同じ内容のURLをまとめて扱い、代表となるURLのみがインデックスされることがあります。
つまり、クロールされたからといってすべてのページがインデックスされる訳ではないということです。
技術要件を満たしていても、必ずインデックス登録されるわけではありません。ページの品質が低い場合やガイドライン違反がある場合は、インデックス登録されない可能性があります。
Googleクローラーに巡回申請する方法
Googleのクローラーに巡回申請する方法は以下の2つです。
Googleサーチコンソールからインデックス登録リクエストを行う
XMLサイトマップを送信する
大前提として、GoogleクローラーはWebサイト上にあるリンクをたどって自動的に世界中のページを発見し巡回していますが、上記2つのいずれかの方法を行うことで、サイト運営者側からGoogleのクローラーに対して巡回申請を行うことができます。
それぞれ詳しく解説します。
Googleサーチコンソールからインデックス登録リクエストを行う
Googleサーチコンソールにある「URL検査」という機能を使うことでGoogleクローラーに直接クロール申請を行うことができます。
Googleサーチコンソールにログインして、左メニュー内にある「URL検索」をクリックします。
上部の検索窓にクロール申請したいページのURLを入力して[Enter]を押します。

画面が遷移したら「インデックス登録をリクエスト」ボタンをクリックします。
これでGoogleクローラーへのクロール申請は完了です。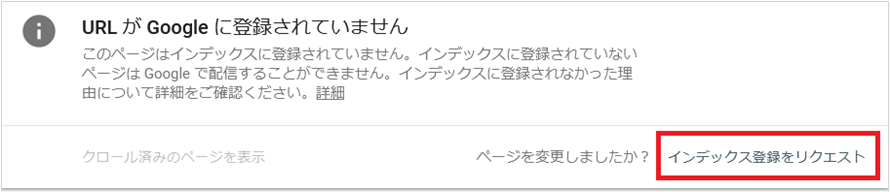
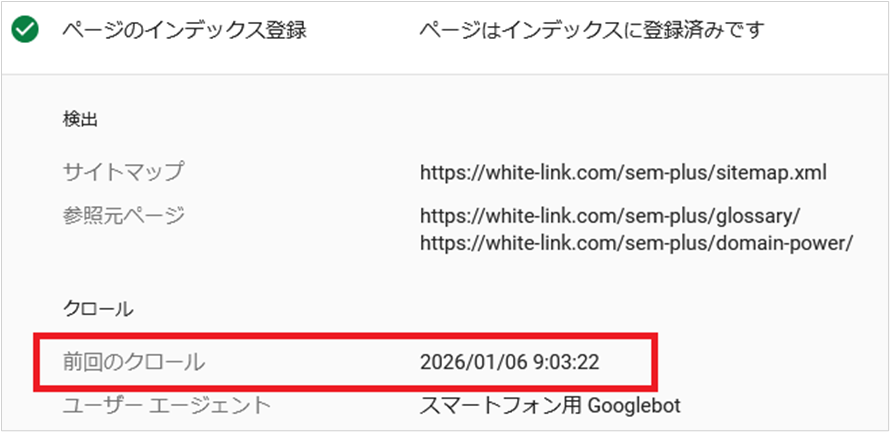
少し時間を開けてから「ページのインデックス登録」を開き「前回のクロール」を見るとGoogleクローラーがクロールを行ったかどうかわかります。
以下画像のように日時が表示されてればクロールされています。
▼ URL検査については別の記事でも詳しく解説しています。
XMLサイトマップを送信する
GoogleサーチコンソールからXMLサイトマップを送信すると、サイト内にあるURLの存在をまとめてGoogleに伝えられます。つまり、Googleが新規・更新ページを発見しやすくなるため、間接的にクロールを促す効果が期待できます。
Googleサーチコンソールにログインして、左メニューの[サイトマップ]を開く
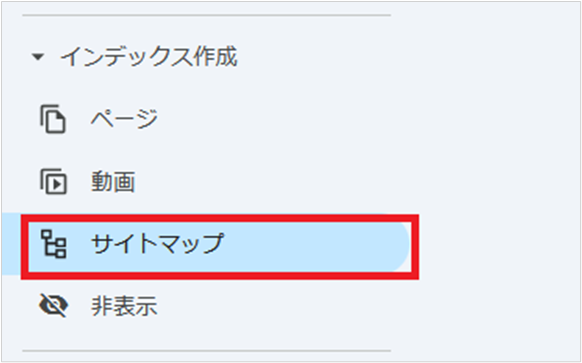
サイトマップのURLを入力して[送信]をクリックします。

送信後のステータスを確認して「成功しました」と表示されれば完了です。
▼ GoogleサーチコンソールからXMLサイトマップを送信する方法については別の記事で詳しく解説しています。
Googleクローラーが巡回したか確認する方法
GoogleクローラーがWebサイトを巡回したか確認する方法も主に次の2つです。
Googleサーチコンソールで確認する
サーバーログで確認する
それぞれ詳しく解説します。
Googleサーチコンソールで確認する
Googleサーチコンソールを使うことでクローラーがページを巡回したか確認することができます。
- 特定のURLに対しての巡回を確認したい場合
-
「URL検査」で確認する
- 複数のURLに対しての巡回を確認したい場合
-
「ページのインデックスレポート」で確認する
それぞれの確認方法は以下になります。
URL検査(特定URLの確認をする)
URL検査では、対象URLがGoogleでどのように扱われているかを確認できます。
「ページのインデックス登録」の項目には、クロールが許可されているか、最終クロール日時などが表示されます。

また「公開URLをテスト」を使うと、現時点のページをGoogleが取得できるかを確認できます。
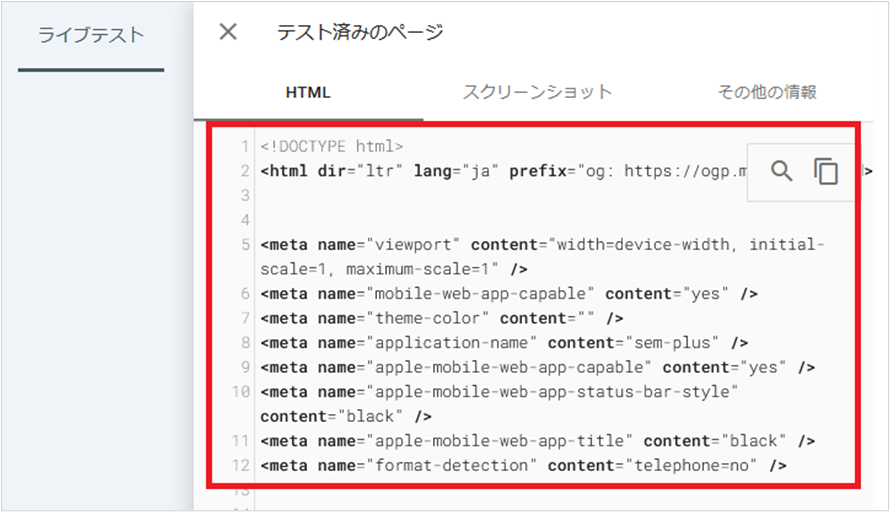
URL検査からクローラーが巡回したか確認する手順は以下になります。
サーチコンソールにログインして、左メニューから「URL検索」をクリック
上部の検索窓に確認したいURLを入力
画面上に表示された「ページのインデックス登録」をクリック
展開されるのでステータスを確認
ページのインデックスレポート(サイト全体の傾向)
「ページのインデックスレポート」は、Google が検出したURLのうち、インデックスに登録できたもの/できなかったものと、登録できなかった理由をサイト全体で確認できるレポートです。
あくまで、インデックス状況を確認するためのものですが、インデックス登録済みのURLは、少なくともGoogleにクロールされた実績があると考えられます。
また、レポートのURL一覧では、各URLの最終クロール日時も確認できます。
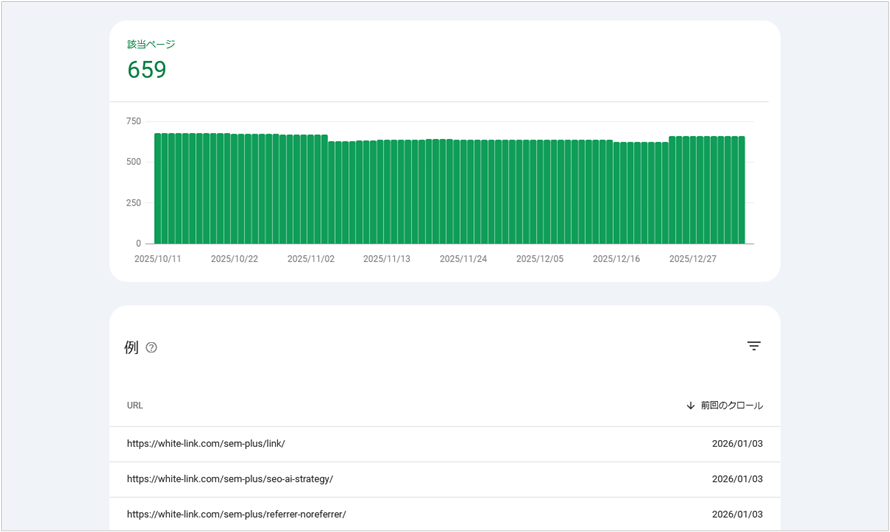
▼ 「ページのインデックスレポート」を確認する手順は以下になります。
サーチコンソールにログインして、左メニューにある「インデックス作成」内の「ページ」をクリック
「インデックス済みのページのデータを表示」をクリック
インデックス登録済みのURLが一覧で表示されます。
サーバーログで確認する
サーバーログは、サイトに来たアクセスを「いつ・どのURLに・どんな結果で」処理したかを残す履歴です。
Googleクローラーのアクセスも同じように記録されるため、ログを見れば「どのページが実際にクロールされているか」「更新したページに取りに来ているか」「404やサーバーエラーでクロールを失敗していないか」を具体的に追うことができます。
サーチコンソールは全体像を掴むのに便利ですが、サーバーログは「現場の証拠」に近い情報です。サーバーログを確認するには多少の知識が必要な一方、クロールの偏りや無駄な巡回、ボトルネックを発見しやすいので、ページ数が多いサイトや技術面の改善を進めたい場合にはサーバーログからクローラーの巡回を解析をすることをおすすめします。
Googleクローラーによるクロール量の増減を確認する方法
Googleクローラーのクロール量が増えた/減ったかを確認したい場合は、Googleサーチコンソールの「クロール統計情報」を利用します。クロール統計情報はサイト全体の総クロールリクエスト数の推移が確認できるため、クロール量の増減を把握できます。
▼ 確認する手順は以下になります。
Googleサーチコンソールにログインし、左メニュー下部の「設定」をクリックします。
「クロール」欄の「クロールの統計情報」で「レポートを開く」をクリックします。

画面上部のグラフで「クロール リクエストの合計数」の推移を見て、増減を確認します。
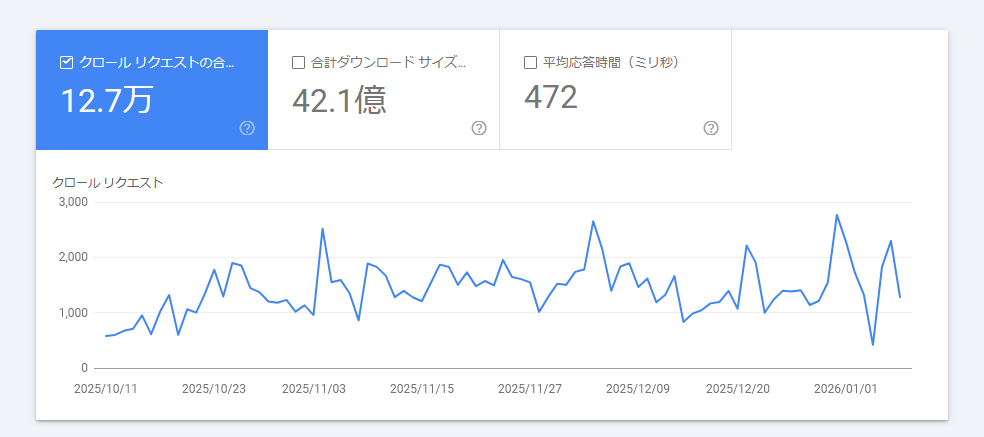
急な増減があれば、同レポート内の「クロール リクエストの詳細」にある「レスポンス別」を見てサーバーエラーが発生していないかなどを確認し原因の当たりを付けます。
▼ クロールの統計情報については別の記事で詳しく解説しています。
Googleクローラーの巡回を拒否する方法
Googleクローラーの巡回を拒否する方法は、主にrobots.txtと.htaccessの2つがあります。どちらも「見せたくないページを守る」ための手段ですが、目的によって適切な使い分けが必要です。
例えば、管理画面・テスト環境・会員限定ページなど、検索に載せる必要がないページはrobots.txtを使ってクロール対象から外した方が適しています。
一方で、外部に公開したくない情報が含まれているページや、テスト環境など絶対に閲覧されると困るページは、robots.txtではなく.htaccessでパスワードをかけてクローラーからのアクセス自体を遮断する方が確実です。
robots.txtと.htaccessでGoogleクローラーの巡回を拒否する方法について詳しく解説します。
robots.txtを使用して拒否する
robots.txtは、検索エンジンのクローラーに対してどのURLをクロールしてよいか/しないかを伝えるためのファイルです。
設定次第で、Googlebotだけを拒否したり、特定ディレクトリ配下のクロールを拒否したりできます。
▼ robots.txt の基本的な書き方の例は以下になります。
User-agent: Googlebot
Disallow: /xxx/User-agentには、対象にしたいクローラー名を書きます(例:Googlebot)。
Disallowには、クロールを拒否したいパスを書きます。パスは 大文字・小文字を区別します。
Disallow: / とするとサイト全体を拒否します。
User-agent: * とするとすべてのクローラーが対象になります。
なお、robots.txtはクロールを制御するもので、インデックス登録を確実に防ぐものではありません。リンクなどからURLが見つかると、ページ内容をクロールできなくてもURLのみが検索結果に表示される場合があります。
インデックスを拒否したい場合はnoindex(meta robots/X-Robots-Tag)を使用するようにしましょう。
▼ robots.txt については別の記事で詳しく解説しています。
.htaccessを使用して拒否する
.htaccessは、Apacheサーバーで 特定のアクセスを拒否したり、認証をかけたりすることができる設定ファイルです。
robots.txtと違って「クロールしないでね」ではなく、物理的にページにパスワードをかけるなどアクセスさせないという強い制御ができます。そのため、.htaccessでパスワードをかける方法が、クローラーにページ内容を読み込ませない方法として一番確実な方法となります。
ただし、.htaccessでパスワードをかけた場合、Googlebotだけでなくパスワードを知らないユーザーもページを見られなくなります。
▼ .htaccess については別の記事で詳しく解説しています。
Googleクローラーの頻度を高めるための方法
Googleクローラーの巡回頻度(=クロール量)を増やすには、「設定で無理やり上げる」というより、Googleが「もっと巡回しに行きたい」と思う状態にするのが基本です。
「クロールの必要性」 とはサイトの人気度や重要度、更新の多さなどのことで、ユーザーにとって価値が高く高品質で人気のサイトであればクロール頻度が高くなります。
「クロール頻度の制限」とは、Googlebotがサイトに対して行うクロールがサーバーに負荷をかけすぎないように、取得ペースに上限をかけることを指します。そのため、ページの表示速度やサーバーの応答速度が影響します。
そのため、次の6の方法を実践することでGoogleクローラーの巡回頻度を高めることができます。
重複コンテンツを削除する
低品質なぺージを削除する
ページの品質を高める
サーバーの応答速度を改善する
ページの表示速度を改善する
内部リンクを最適化する
それぞれ詳しく解説します。
重複コンテンツを削除する
重複コンテンツとは、サイト内のぺージ同士で内容が類似または重複しているコンテンツのことです。
▼ 具体的に重複コンテンツとは以下のようなページが該当します。
URLは違うが内容がほぼ同じページ(同一記事の別URL、複製ページなど)
パラメータ違いで中身が同じページ(例:?sort=?ref=?utm_などで表示内容が変わらない)
並び替え/絞り込みで生成される類似ページ(商品一覧・求人一覧などで差分が小さい)
カテゴリ/タグ/アーカイブが似た内容になっているページ(同じ記事集合を別軸で表示)
PC版・スマホ版など、別URLで同内容を出しているページ
http/https、www有無、末尾スラッシュ有無などの表記ゆれで生まれる同内容ページ
印刷用ページ・AMP・テスト用URLなど、同内容の派生ページ
ページネーション(?page=2など)で重複が多い一覧ページ(1ページ目と差分が薄い)
▼ 重複コンテンツが発生した場合は以下の方法で対処しましょう。
- リダイレクトを行いURLを統合する
-
双方のページを見せる必要がなく、完全に1つのURLに集約したい場合
- canonicalタグを使ってURLを正規化する
-
URLは複数存在してもよいが、Googleには「評価の中心となるURL」を伝えて代表URLに集約したい場合
- 重複したページを削除する
-
検索にもユーザーにも価値が薄く、今後も使わないページなので、URL自体をなくして整理したい場合
低品質なぺージを削除する
低品質なページがサイト内に大量にあると、クローラーが巡回すべきURLが増えて重要ページのクロールが分散したり、サイト全体の品質評価にも悪影響が出る可能性があります。
そのため、成果に繋がらないページや維持する価値が低いページは、削除してサイト全体の品質を高めることが重要です。
具体的に低品質なページとは、ユーザーにとって得られる情報が少なく、検索意図を十分に満たせていない以下のようなページのことです。
内容が薄いページ
競合他社のページとほぼ同じ内容のページ
古い情報のまま更新されていないページ
ページの品質を高める
ページの品質が高いほどユーザーの満足度が高くなるため、Googleは検索で重要なページだと判断します。
重要度が高いページはクロールの優先度やクロールの上限値も上がりやすいため、ページの品質を高めることで間接的にクロール頻度の向上に繋がります。
実際にGoogle公式ドキュメントには以下の趣旨が記載されています。
ターゲットとする Google のプロダクトに合わせてコンテンツの品質を最適化しましょう。Google は、各サイトに割り当てるクロールのリソースを、その Google プロダクトに関連する要素を考慮して決定します。たとえば Google 検索の場合、人気度、ユーザーにとっての総合的な価値、コンテンツの独自性、配信(提供)能力などが含まれます。
クロール バジェット管理
※ SEM Plus編集部和訳
ページの品質を高めるには次の要素を意識してコンテンツを改善します。
- 検索意図を満たす
-
ユーザーが知りたい内容を記載し疑問が解決できる内容にする
- 独自性を高める
-
一次情報(実体験・事例・データ)や自社ならではの視点を追加する
- 情報の正確性と鮮度
-
古い情報の更新、根拠の明記、誤字脱字の修正を行う
- 内容の網羅性
-
比較・手順・注意点・FAQなど、意思決定に必要な情報を揃える
- 読みやすさ
-
見出し構造、図表、箇条書きを使いユーザーが内容を理解しやすくする
- 信頼性の担保
-
運営者情報、監修者、引用元、問い合わせ先などを明確にする
サーバーの応答速度を改善する
サーバーの応答が遅かったり、500番台のエラーが多発したりすると、Googlebotはサーバー負荷を避けるために自動的にクロール頻度を下げることがあります。
Googleの公式ページには以下のように記載されています。
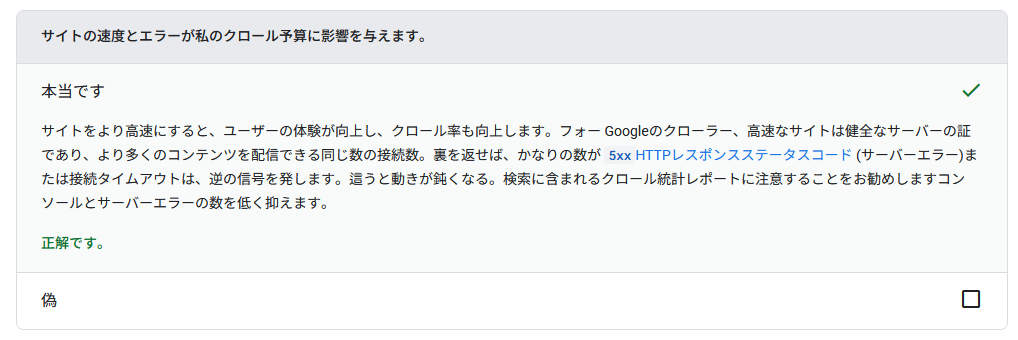
そのため、契約しているサーバープランが低く高負荷に耐えられない場合は、上位プランへの変更やスケールアップ、キャッシュの導入、DB/アプリのボトルネック改善などで応答速度を改善するのが有効です。
改善の効果を確認したい場合は、Googleサーチコンソールの 「クロール統計情報」 で、平均応答時間やエラーの増減、クロール量の推移をチェックしましょう。
数値が改善していれば、クロール頻度が高まっていると言えます。
ページの表示速度を改善する
ページの表示速度が遅いと、Googlebot がページ取得に時間を要してしまうため、サイト全体のクロール効率が下がる可能性があります。
具体的には画像・JavaScript・CSS などのリソースが重いページが多いと、クロールに時間がかかり、重要ページの巡回が後回しになることがあります。
そのため、ページ表示速度の改善は、ユーザー体験だけでなくクロール効率の観点でも重要です。まずは、ページの表示速度を計測するツールPageSpeed Insightsでページの表示速度を確認してみましょう。
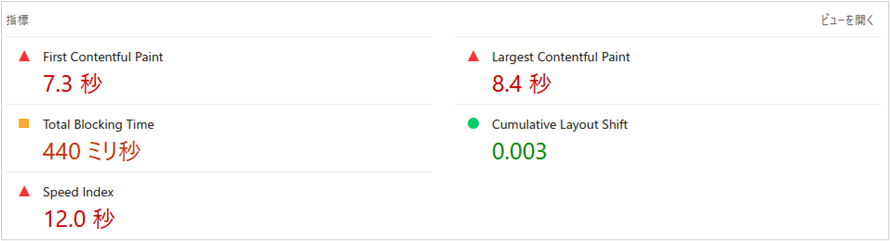
ページの表示速度に問題がある場合は、以下の方法で改善します。
画像の圧縮、WebP化、遅延読み込み
JavaScriptの削減・分割、不要スクリプトの停止
CSSの軽量化、未使用CSSの削除
ブラウザキャッシュやCDNの活用
▼ 具体的な改善方法については別の記事で詳しく解説しています。
内部リンクを最適化する
内部リンクの最適化とは、サイト内で重要なページに内部リンクを集めたり、孤立したページを作らない施策のことを指します。
重要ページに内部リンクを集めることで、サイト内での重要度が伝わりやすくなり、重要ページが優先的に巡回されやすくなります。
また、価値の低い派生URLや重複ページにクロールが偏るのを防ぎ、クロールの無駄を減らすことにもつながります。さらに、新規公開ページや更新ページが孤立していると、GoogleがURLを発見するまでに時間がかかることがあります。
その場合でも、すでにクロールされている関連ページから内部リンクを張っておけば、Googlebotがリンクを辿ってURLを見つけやすくなります。
重要ページへリンクを集める
関連性の高いページ同士をつなぐ
孤立ページを作らない
アンカーテキストを具体的にする
Googleクローラーに関するよくある質問
クロールの頻度を制御する方法はありますか?
サイトに訪れるクローラーの巡回頻度を制御する方法はありません。
以前はGoogleサーチコンソールの「クロール頻度制限ツール」からクロール頻度を制限することができましたが、2024 年 1 月 8 日にツールの提供が終了となっています。
リンク先URLのクロールを防ぐ方法は?
発リンクを設置した際に、リンク先のページのクロールを防ぎたい場合は、nofollowタグを利用します。
nofollowタグは「href属性」で指定したリンク先をクロールさせない命令文のため、nofollowタグに記述されたURLをクローラーは原則巡回しなくなります。ただし、nofollowを設定したからといって絶対にクロールしないわけではありません。
クロールバジェットとは何ですか?
クロールバジェット(crawl budget)とは、Googleがサイトに対して「クロールできる」かつ「クロールしたい」と判断したURLの量のことです。サーバーの状態と、コンテンツの重要度や更新性などによって変動します。
GoogleクローラーのIPアドレスは?
GooglebotのIPアドレスは以下のページから確認することができます。
https://developers.google.com/search/apis/ipranges/googlebot.json
なお、IPアドレスは変更される可能性があるため、定期的に確認するようにしましょう。
まとめ
今回は、Googleのクローラーについて解説しました。
クローラーによるページの巡回がされなければ、インデックスされずページが検索結果に表示されません。クローラーの仕組みと役割を正しく理解することで、インデックスがされない原因と改善策を考えることができるようになるため、クローラーについて知ることはサイトを運営する上では重要な意味を持ちます。
特にSEO対策を行う場合や、大規模サイトを運用する場合は、クロールをコントロールする必要があるため、本記事でしっかりとクローラーについて覚えておくようにしましょう。
この記事を書いたライター

SEMを軸にSEOの施策を行うオルグロー内の一部署。 サイト構築段階からのSEO要件のチェックやコンテンツ作成やサイト設計までを一貫して行う。社内でもひときわ豊富な知見を有する。またSEO歴15年超のノウハウをSEOサービスに反映し、3,000社を超える個人事業主から中堅企業までの幅広い顧客層に向けてビジネス規模にあった施策を提供し続けている。
ぜひ、読んで欲しい記事
-
 SEO対策PageSpeed Insightsの見方(使い方)│警告の意味と改善方法を解説2026/03/06
SEO対策PageSpeed Insightsの見方(使い方)│警告の意味と改善方法を解説2026/03/062026/03/06
-
 SEO対策Googleインデックスとは?インデックス登録されない原因と対処方法を解説2026/03/06
SEO対策Googleインデックスとは?インデックス登録されない原因と対処方法を解説2026/03/062026/03/06
-
 SEO対策セマンティック検索とは?Google SEOで重要な意味理解の仕組みを解説2026/03/05
SEO対策セマンティック検索とは?Google SEOで重要な意味理解の仕組みを解説2026/03/052026/03/05
-
 SEO対策【2026年最新】検索エンジン一覧│世界と日本での人気ランキング2026/03/03
SEO対策【2026年最新】検索エンジン一覧│世界と日本での人気ランキング2026/03/032026/03/03
-
 SEO対策robots.txtとは?書き方と設定場所・確認方法を解説2026/02/27
SEO対策robots.txtとは?書き方と設定場所・確認方法を解説2026/02/272026/02/27
-
 SEO対策nofollowとは?設定方法と設定例・利用するケースと注意点を解説2026/02/25
SEO対策nofollowとは?設定方法と設定例・利用するケースと注意点を解説2026/02/252026/02/25