robots.txtとは?書き方と設定場所・確認方法を解説

「robots.txt」とは検索エンジンのクローラーがページをクロールするのを管理するためのファイルです。「どのような場面で使用するのか?」「どのように設定するのか?」「noindexタグとの違いは何か」など、疑問に感じている方も多いのではないでしょうか?本記事では、robots.txtの意味や使い方について詳しく解説します。

robots.txtとは
robots.txtとは、検索エンジンや生成AIのクローラーに対して、「サイトのどのURLを見てよいか/見ないでほしいか」を伝えるためのファイルです。
Googleのクローラーは、URLを見つけると最初にrobots.txtにアクセスしてクロールが許可されているかを確認します。クロールしてほしくないページがある場合は、robots.txtでクロールを控えるように指示できます。
例えば、大規模サイトのSEOでは特定のURLやディレクトリのクロールを制御することで、不要なURLへのクロールを減らし、重要なページがクロールされやすい状態を作るために利用されます。
その他にも、次のような用途でrobots.txtが利用されます。
管理画面・会員ページをクロールさせたくない
サイト内検索ページをクロールさせたくない
テスト環境をクロールさせたくない
特定のBotだけクロールを制御したい
sitemap.xmlの場所を伝えたい
ただし、robots.txtを設定したからといってすべてのクローラーが必ず従うとは限りません。
robots.txtでできること/できないこと
robots.txtは、クローラーの巡回範囲をコントロールするためのファイルですが、できることとできないことがあります。
| できること | できないこと |
|---|---|
| 特定のURLやディレクトリのクロールを制御できる | 検索結果からページを削除することはできない |
| 特定のクローラーだけクロールを制御できる | ページを非公開にすることはできない |
| sitemap.xmlの場所をクローラーに伝えられる | アクセス制御(ログイン・IP制限など)はできない |
robots.txtは「クロール制御」の仕組みであり、「検索結果に出さないインデックス制御」や「見せないアクセス制御」の仕組みではありません。
インデックスを制御する場合はnoindexタグを使用し、アクセス制御をしたい場合は認証をおこなう必要があります。
robots.txtでできることと、できないことを理解して使うことが重要です。
robots.txtの書き方の基本
robots.txtは「対象のクローラー」+「クロールさせたくないURL」を書くだけです。
基本は、次のルールを組み合わせて記述します。
| 項目 | 何を書くか | 役割 | 記述例 |
|---|---|---|---|
| User-agent | 対象にするクローラー | どのBotに対するルールか指定 | User-agent: * |
| Disallow | クロールさせたくないURL | クロール拒否 | Disallow: /admin/ |
| Allow | クロールを許可するURL | Disallowの例外許可 | Allow: /images/public/ |
- User-agent
-
対象にするクローラーを指定
- Disallow
-
クロールを拒否したいURLを指定
- Allow
-
例外的にクロールを許可したいURLを指定(必要な場合のみ)
User-agentの書き方
「User-agent」は、制御するクローラーを指定する項目です。robots.txtでは通常、最初にUser-agentを記述します。
User-agent: *User-agent: Googlebot・User-agent: Googlebot
# ここにGooglebotに対する指示を書く
・User-agent: Bingbot
# ここにBingbotに対する指示を書くDisallowの書き方
「Disallow」は、クローラーにクロールしてほしくないURL(ディレクトリ/ファイル)を指定する項目です。
Disallow:のあとを空欄にすると、そのUser-agentに対してクロールを禁止しないことを意味します。
Disallow: /Disallow: /seo/Disallow: /directory/file.htmlAllowの書き方
「Allow」は「Disallow」で禁止した範囲の中で「このURLだけは許可したい」という例外を作るときに使います。記述は任意ですが、AllowはDisallowとセットで使うのが基本です。
User-agent: *
Disallow: /images/
Allow: /images/public/上記はすべてのクローラーに対して、/images/ ディレクトリ以下のクロールを禁止。
ただし、/images/public/ ディレクトリ以下のURLはクロールを許可します。という意味になります。
robots.txtケースごとの書き方例8選
robots.txtは、サイトの状況や目的に応じて設定内容が変わります。本章では、実務でよく使われる代表的なケースごとの書き方例を紹介します。
管理画面をクロールさせたくない場合
開発環境でサイト全体をクロールさせたくない場合
特定のBotだけクロールを制御したい場合
AIクローラーをまとめてブロックしたい場合
画像は基本クロールさせないが「公開用」だけ許可したい場合
URLパラメータ付きページのクロールを抑制したい場合
PDFやダウンロードファイルのクロールを抑制したい場合
サイトマップの場所をクローラーに伝えたい場合
それぞれ詳しく解説します。
管理画面をクロールさせたくない場合
CMSの管理画面をクロールさせたくない場合は以下のように記述します。
User-agent: *
Disallow: /admin/管理画面は検索結果に出す必要がなく、クロールされると無駄な巡回が増えます。User-agent: * で全てのクローラーを対象にし、Disallowで管理画面のURLをクロールしないよう指示します。※/admin/ は管理画面のURLがこの配下にある想定です。
開発環境でサイト全体をクロールさせたくない場合
テスト環境やステージング環境をクローラーに巡回させたくない場合は、以下のように記述します。
User-agent: *
Disallow: /User-agent: * で全てのクローラーを対象にし、Disallow: / でサイト全体をクロールしないよう指示します。
/ はサイト全体を意味するため、本番(公開サイト)のrobots.txtに入れると、全ページがクロール対象から外れる点に注意してください。
特定のBotだけクロールを制御したい場合
特定のクローラーにだけクロール制御をかけたい場合は、以下のように記述します。
User-agent: Googlebot
Disallow: /private/User-agent: Googlebot でGoogleのクローラーだけを対象にし、Disallow で /private/ 配下をクロールしないよう指示します。
Googleには巡回させたくない一方で、他のクローラーには別のルールを適用したい場合に利用します。
※/private/ は対象URLがこの配下にある想定です。
AIクローラーをまとめてブロックしたい場合
AIによる学習やクロールを制御したい場合は、AI関連クローラーごとに指定して記述します。
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /特定のAIサービスにクロールされたくない場合にはAIクローラーごとにUser-agentを指定し、Disallow: /でサイト全体をクロールしないよう指示します。
※AIクローラーは複数存在するため、必要に応じて対象クローラーを追加します。
- GPTBot
-
OpenAI(ChatGPTなど)の学習データ収集に使われるクローラー
- Google-Extended
-
GoogleのAI(生成AI・AI学習用途)向けのクローラー
- ClaudeBot
-
Anthropic(Claude)の学習データ収集に使われるクローラー
- PerplexityBot
-
Perplexity AIの検索・回答生成に使われるクローラー
画像は基本クロールさせないが「公開用」だけ許可したい場合
装飾用画像や管理用画像など、検索に出す必要がない画像が多い一方で、公開用の画像だけはクロールさせたい場合は、以下のように記述します。
User-agent: *
Disallow: /images/
Allow: /images/public/Disallowで/images/配下のクロールを禁止し、Allowで/images/public/配下だけ例外的にクロールを許可します。
Allowは「Disallowで禁止した範囲の中で、このURLだけは許可したい」という例外を作るための項目です。
※画像検索からの流入を狙う画像がある場合は、対象に含めないよう注意してください。
URLパラメータ付きページのクロールを抑制したい場合
並び替えや絞り込みなどでURLが大量に増える場合は、以下のように記述します。
User-agent: *
Disallow: /*?sort=
Disallow: /*?filter=並び替えや絞り込みのURLは内容が似ていることが多く、クロール対象となるページが増えすぎる原因になります。不要なURLのクロールを減らしたい場合に利用します。
また、重複するページが大量にあると、検索エンジンがどのURLを優先して評価すべきか分かりにくくなります。パラメータURLは数が増えやすいため、大規模ECサイトやポータルサイトでは重要な対策になります。
PDFやダウンロードファイルのクロールを抑制したい場合
PDFなど検索結果に出す必要がないファイルをクロールさせたくない場合は、以下のように記述します。
User-agent: *
Disallow: /*.pdf$$ は「その文字列でURLが終わる」という意味です。そのため /*.pdf$ と書くと、「.pdf で終わるURLだけ」を対象にできます。
例えば file.pdf は対象になりますが、file.pdf?download=1 のようにパラメータが付くURLは対象外になります。
また、ダウンロードファイルには PDF 以外にも、Excel(.xlsx)、Word(.docx)、ZIP(.zip)などがあります。これらも同様に、拡張子ごとに指定してクロールを制御できます。
Disallow: /*.xlsx$
Disallow: /*.docx$
Disallow: /*.zip$
サイトマップの場所をクローラーに伝えたい場合
robots.txtには、クロール制御の設定だけでなく、サイトマップ(sitemap.xml)の場所をクローラーに伝えるための「Sitemap」という記述項目もあります。
クローラーにサイトマップの場所を伝えたい場合は、以下のように記述します。
Sitemap: https://example.com/sitemap.xmlサイトマップは絶対URL(httpsから始まるURL)で記述します。また、複数のサイトマップがある場合は、複数行に分けて記述できます。
Sitemapは、サイト内のページ一覧をまとめたファイルの場所をクローラーに知らせるための設定です。robots.txtに記述することで、クローラーがサイトマップを見つけやすくなり、サイト構造を把握しやすくなります。
robots.txtの設置場所
robots.txtは、Webサイトのルートディレクトリ(ドメイン直下)に設置します。ファイル名は必ず「robots.txt」にしてください。
例えば、トップページが https://white-link.com/ なら、robots.txtは次の場所です。
https://white-link.com/robots.txthttps://example.com/folder/robots.txt
https://example.com/assets/robots.txtルートディレクトリの直下ではないため、robots.txtとして認識されません。
https://example.com/robots.txt
https://shop.example.com/robots.txtサブドメインの場合はサブドメインごとにrobots.txtの設置が必要です。
robots.txtを作成しても、正しい場所に設置しなければクローラーには読み取られません。そのため、設置場所のルールを理解しておくことが重要です。
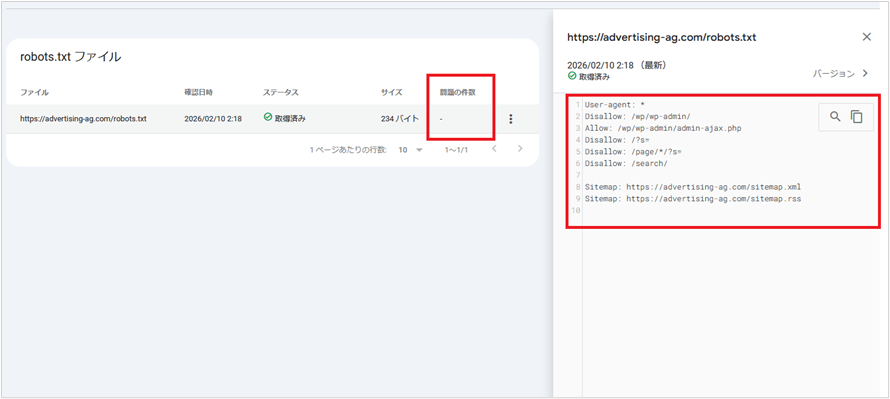
Googleがrobots.txtを取得できているか確認する方法
robots.txtファイルをサーバーにアップロードしたら、Google Search Consoleの「robots.txt レポート」で正しく取得できているかを確認します。
以下の手順で、Googleがrobots.txtを取得できているか確認できます。
Google Search Console にログイン
左メニューの下にある 「設定」 をクリックして「robots.txt」 をクリック
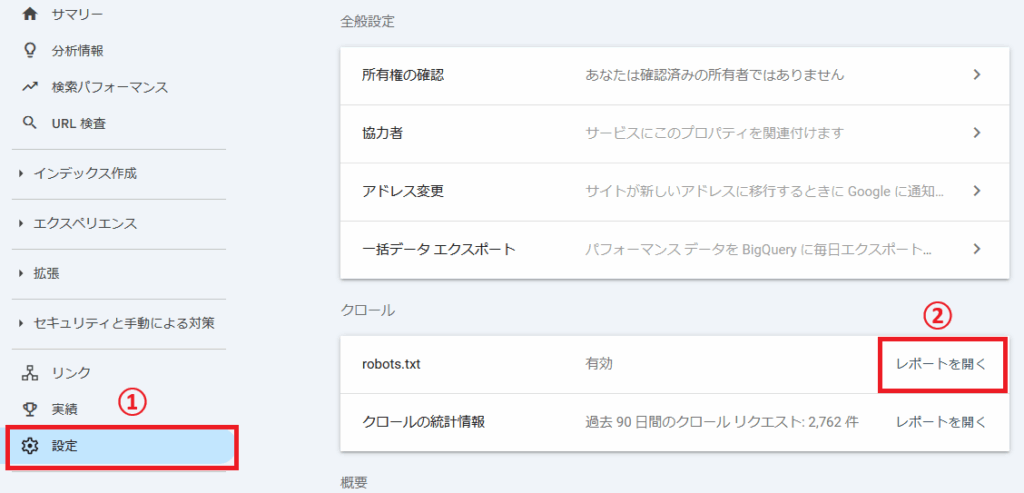
「取得ステータス」 を確認
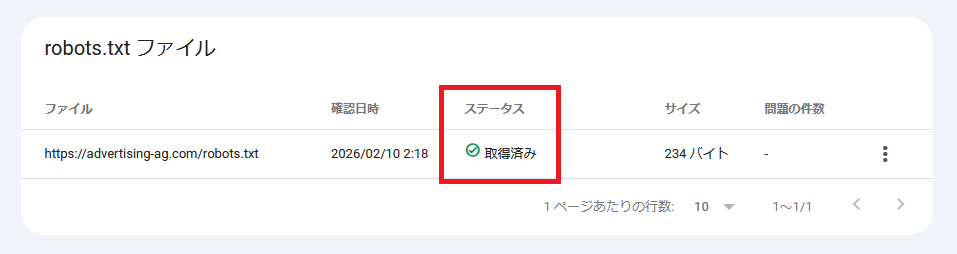
ステータスが「取得済み」になっていればGoogleのクローラーはrobots.txtを正常に取得できています。
一方で以下のステータスになっている場合は何らかのエラーが発生しています。
- 未取得 - 見つかりませんでした(404)
-
設置場所やファイル名が誤っている可能性があります。
- 未取得 - その他の理由
-
アクセス制限やサーバーエラーの可能性があります。
取得エラーが発生している場合は、robots.txtレポート内の「問題の件数」に数値が出ることがあります。
robots.txtでよくある設定ミス6選
robots.txtを設定した際に、意図せずクロール範囲を広く制限してしまったり、期待通りに制御できていないケースがあります。
実務で特に起こりやすい設定ミスは以下の6つです。
Disallowの範囲を広く書きすぎる
Allowを書けば必ず優先されると思っている
開発環境用robots.txtを本番に出してしまう
robots.txtで非公開にできると思っている
noindexとrobots.txtを併用している
CSS・JS・画像をブロックしている
それぞれ詳しく解説します。
Disallowの範囲を広く書きすぎる
Disallow: /blogこのように記述すると、/blog/ ディレクトリだけを止めたつもりでも、/blog-old/ や /blog2024/ など、/blog から始まるURLまで対象になる可能性があります。
これは、robots.txtが基本的に「前方一致」で判定されるためです。特定のディレクトリだけを対象にしたい場合は、/blog/ のように末尾のスラッシュまで含めて記述する方が安全です。
Allowを書けば必ず優先されると思っている
User-agent: *
Disallow: /images/
Allow: /public/Allowは「Disallowで禁止した範囲の中で、例外的に許可したいURL」を指定するための項目です。
上記例のように禁止範囲(/images/)と無関係な場所(/public/)をAllowしても、/images/ 配下の例外にはならず、意図した動作にならないことがあります。
例外を作りたい場合は、Disallowで禁止した範囲の中のURL(例:/images/public/)をAllowで指定する必要があります。
開発環境用robots.txtを本番に出してしまう
User-agent: *
Disallow: /上記はサイト全体のクロールを禁止する設定です。開発環境やステージング環境では有効ですが、本番用のサイトに入ってしまうと、重要なページも含めてすべてのページがクロール対象から外れてしまいます。
特にデプロイ時のファイル上書きや環境切り替えのミスで起きやすいため、公開前に必ず https://example.com/robots.txt とSearch Consoleの取得ステータスを確認しておくと安全です。
robots.txtで非公開にできると思っている
User-agent: *
Disallow: /private/robots.txtは「クロールを控えてほしい」という指示であり、ページを非公開にする仕組みではありません。
URLを知っていればブラウザからアクセスできるため、機密性のあるページを守る目的には使えません。管理画面や会員ページなど、本当に見せたくないページは、認証やアクセス制限で保護する必要があります。
また、robots.txtでクロールを禁止していても、外部サイトからリンクされている場合などは、URLだけが検索結果に表示されるなど、インデックスされる可能性があります。
そのため、「検索結果に表示させたくない」場合は、noindexや認証制御などを併用する必要があります。
noindexとrobots.txtを併用している
robots.txtとnoindexタグを併用してはいけません。
インデックスさせたくないページにnoindexを付与しても、robots.txtでクロールを禁止している場合は検索エンジンはページをクロールできないため、noindexタグを確認することができません。
そのため、「検索結果から削除したいページ」に対していきなりrobots.txtでブロックするのはNGです。
正しい手順は以下の通りです。
まずnoindexを設置する
クローラーにクロールさせる
検索結果から消えたことを確認する
その後、必要ならrobots.txtでクロールを止める
CSS・JS・画像をブロックしている
CSS・JavaScript・画像をrobots.txtでブロックすると、検索エンジンがページを正しく理解できなくなる可能性があります。
現在のGoogleはHTMLだけでなく、CSSやJavaScriptも読み込んで、実際の表示に近い状態でページを評価しています。そのため、レンダリングに必要なリソースをブロックすると、レイアウト崩れやコンテンツ未取得が発生し、SEO評価に影響することがあります。
そのため、基本的に 「CSS」「JavaScript」「重要な画像(商品画像・メイン画像など)」はブロックしない方が安全です。
robots.txtに関するよくある質問
robots.txtを設置していないとどうなるのか?
robots.txtを設置していない場合、クローラーは「クロールを制限する指示がない」と判断し、サイト内のURLを自由にクロールします。
また、robots.txtを設置していない場合でも、検索エンジンがインデックスを行うこと自体には影響はありません。そのため、クロールを制御する必要がない場合はrobots.txtを設置していなくても問題ありません。
robots.txtとnoindexの違いは何か?
robots.txtがクロール自体を制限するファイルなのに対して、noindexタグは検索エンジンに対してインデックスを拒否する指示をおこなうために使用するHTMLタグです。
| robots.txt | noindexタグ | |
|---|---|---|
| 役割の違い | クロールを拒否する | インデックスを拒否する |
| インデックスの有無 | インデックスされる可能性がある | インデックスされない |
| クロールの有無 | クロールを拒否できる | クロールされる |
検索結果に表示させたくないページに対しては、robots.txtでクロールを拒否するのではなく、noindexタグを付与しましょう。
▼ noindexタグについては別のページで詳しく解説しています。
robots.txtを設置することでSEO効果はあるのか?
robots.txtを設置しただけで、検索順位が直接上がるといったSEO効果はありません。
そのため、一般的な企業のWebサイトでは、robots.txtを入れたこと自体が順位改善につながるケースはほとんどありません。
ただし、大量のページをインデックスさせる必要がある大規模サイト(ECサイト・ポータルサイトなど)では、robots.txtで不要なページのクロールを抑制することで、重要ページにクローラーのリソースが回りやすくなります。
その結果、重要ページがクロール・評価されやすい状態を作れ、間接的にSEOにプラスに働く可能性があります。
robots.txtはすべてのクローラーが同じように解釈しますか?
いいえ、すべてのクローラーが同じように解釈するわけではありません。
robots.txtは、クローラーに対して「ここはクロールしてよい」「ここはクロールしないでほしい」と伝えるためのルールですが、これは強制命令ではなく「お願い」に近い仕組みです。そのため、検索エンジンごとに解釈が微妙に異なります。
また、すべてのクローラーがルールを守るとは限りません。robots.txtは善意のクローラー向けのルールのため、 悪質なスクレイピングボットや不正アクセスを行うボットは、robots.txtを無視することがあります。
まとめ
今回は、robots.txtでできること・書き方・ケースごとの記述方法について解説しました。
robots.txtは、検索順位を直接上げるための施策ではありませんが、クロールの無駄を減らし、重要なページが適切に評価されやすい状態を作るために重要な役割を持っています。
特に、ECサイトやポータルサイトなどの大規模なデータベース型サイトでは、クロール制御の設計がSEO成果に大きく影響するケースも少なくありません。
一方で、robots.txtはあくまで「クロール制御」の仕組みであり、インデックス制御やアクセス制御とは役割が異なります。また、設定ミスによって重要なページのクロールを止めてしまうリスクもあるため、実装後は必ずSearch Consoleなどで動作確認を行いましょう。
robots.txtの設定が正しいか不安
大規模サイトのクロール最適化をしたい
AIクローラー対策やLLMO観点も含めて最適化したい
といったお悩みがあれば、ぜひ弊社までご相談ください。
この記事を書いたライター

SEMを軸にSEOの施策を行うオルグロー内の一部署。 サイト構築段階からのSEO要件のチェックやコンテンツ作成やサイト設計までを一貫して行う。社内でもひときわ豊富な知見を有する。またSEO歴15年超のノウハウをSEOサービスに反映し、3,000社を超える個人事業主から中堅企業までの幅広い顧客層に向けてビジネス規模にあった施策を提供し続けている。
ぜひ、読んで欲しい記事
-
 SEO対策ページネーションとは│実装方法と実装のポイントを解説2026/04/03
SEO対策ページネーションとは│実装方法と実装のポイントを解説2026/04/032026/04/03
-
 SEO対策スニペットとは?意味・種類とSEOでの設定ポイントを解説2026/04/03
SEO対策スニペットとは?意味・種類とSEOでの設定ポイントを解説2026/04/032026/04/03
-
 SEO対策AMPとは?仕組み・SEO効果・Googleの優遇措置終了について解説2026/04/02
SEO対策AMPとは?仕組み・SEO効果・Googleの優遇措置終了について解説2026/04/022026/04/02
-
 SEO対策SEO対策代行会社おすすめ21選【一覧比較】│失敗しない選び方を解説2026/03/27
SEO対策SEO対策代行会社おすすめ21選【一覧比較】│失敗しない選び方を解説2026/03/272026/03/27
-
 SEO対策リスティング広告とSEOの違いとは?それぞれ向いているケースを解説2026/03/19
SEO対策リスティング広告とSEOの違いとは?それぞれ向いているケースを解説2026/03/192026/03/19
-
 SEO対策画像SEOとは?最適化のポイントと効果計測の方法を解説2026/03/16
SEO対策画像SEOとは?最適化のポイントと効果計測の方法を解説2026/03/162026/03/16